
آخرین مطالب
امکانات وب
شرکت SimpliVity از جمله شرکت های متمرکز بر روی مبحث “hyperconverged infrastructure” بود که شرکت HPE در حدود دو سال پیش به خریداریِ آن اقدام نمود. سیستم های hyperconverged ، پردازش، ذخیره سازی و شبکه را در یک سیستم واحد ترکیب می کنند.
شرکت HPE نرم افزار و سخت افزارِ SimpliVity را با سرورهای پیشرو در صنعت یکپارچه کرده است تا سهمی از بازار زیرساخت های در حال رشدِ Hyper-converged را به چنگ آورد. راهکارهای زیرساخت hyper-converged موجود از شرکت HPE می توانند از افزودنِ تکنولوژی SimpliVity به خود بهره مند گردند که انعطاف پذیری بسیار، data protection ، compression ، deduplication و بهینه سازی VM را با خود به همراه دارد.
شرکت HPE معماریِ پلتفرم SimpliVity Data Virtualization را به عنوان “یک فایل سیستم آگاه و ذخیره سازِ مبتنی بر object به همراه تکنیک های data optimization و data service” توصیف می کند. وجودِ data deduplication و data compression در طراحیِ HPE SimpliVity 380 کارایی مدوامی را در سراسرِ دستگاه فعال می سازد. HPE پلتفرم های سرور پیشرویی را در اختیار دارد که به عنوان پایه ای برای موفقیت HPE SimpliVity به شمار می آیند.

HPE SimpliVity 380
از جنبه سخت افزاری، HPE SimpliVity بر بسترِ مدل های جدید از سرورهای HPE قرار می گیرد. با آنکه هنوز از سرورهای پیشین پشتیبانی می شود، هدف آنها تجمیع بیشتر آن با خطوط محصولاتِ ProLiant و Apollo است تا فرآیندهای پشتیبانی و اعتبارسنجی را ساده سازد. هرچند اساسا هنوز از جنبه سخت افزاری تغییر زیادی رخ نداده است. HPE simplivity 380 یک سیستم با 2U فضا و مبتنی بر سرور DL380 G10 است. این سیستم از OmniStack accelerator card برای انتقال فرآیندهای data reduction (فرآیند کاهش مقدار فضای لازم برای ذخیره سازی داده) از CPU به تراشه ASIC بهره می برد. تمهیدِ OmniStack که مبتنی بر PCIe است قابلیت هایی نظیر caching ، dedupe و compression را فعال می سازد و بخش مهمی از راهکار SimpliVity را تشکیل می دهد. از جمله ویژگی های OmniStack :
- هر نود SimpliVity شامل یک OmniStack accelerator card می شود. همه داده ها بر روی DRAM موجود بر روی آن نوشته می شوند جایی که در آن write تایید شده است، این مشابه با فرآیند caching بر روی SAN است.
- فرآیند compression و deduplication بر روی داده از طریق OmniStack انجام می شود. این مشابه با ایده ی استفاده از ASIC در 3PAR است، با به کار بردن یک قطعه سخت افزاری اضافی، انتقال فرآیندهای مرتبط با این کار به CPU ممکن می شود.

OmniStack accelerator card

محصولات HPE SimpliVity 380 G10
شرکت HPE علاوه بر HPE SimpliVity 380 ، سیستم HPE SimpliVity دیگری مبتنی بر سرورهای Apollo را نیز ارائه نموده است. HPE SimpliVity 2600 حداکثر 4 عدد نود سرور مجزا را درون یک شاسی 2U واحد عرضه می کند. این راهکار بیشتر به منظور استفاده در مواردی همچون دفاتر شعبات سازمان ها (ROBO) ، دفاتر کوچک و VDI طراحی شده است جایی که اپلیکیشن های “حساس به تاخیر” کمتری وجود دارد و زیرساخت می تواند از این شاسی های کوچکتر و اشغال کمترِ فضا بهره مند شود. این راهکارها قابلیت های بکاپ و disaster recovery تعبیه شده ای را در خود همچون بارهای کاری مدیریتی فراهم می کنند.

محصولات HPE SimpliVity 2600

HPE SimpliVity 2600
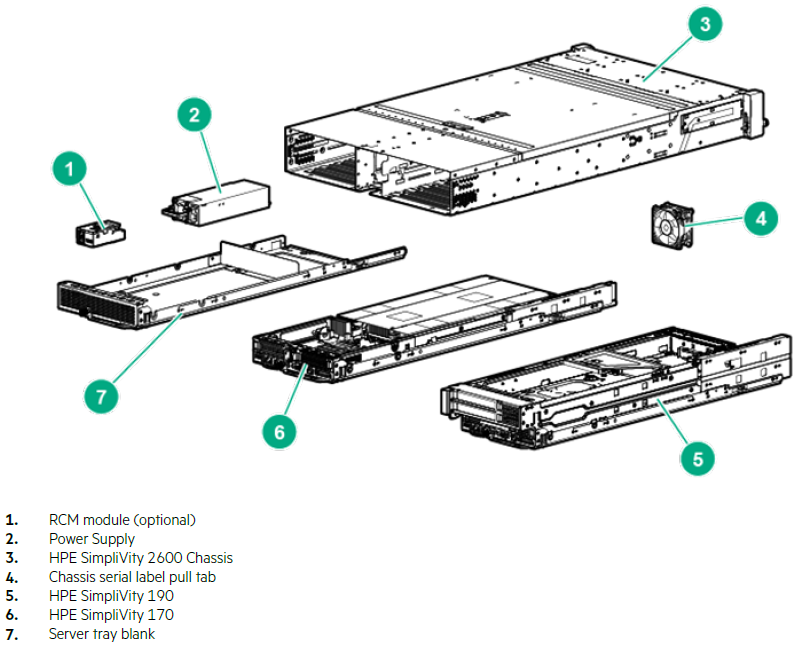
اجزای HPE SimpliVity 2600
برجسته ترین ارزشی که در جدول مشخصاتِ 2600 آمده است پیرامون انعطاف پذیری، سهولت در عملیات و ویژگی های availability است. قابلیت انعطاف پذیریِ آن به منظور پشتیبانی از هر دو هایپروایزرِ Hyper-V و VMware به همراه فضای cloud مخصوص به آنها است. هر چند که امروزه اکثر بیزینس ها بر پایه VMware است، Hyper-V نیز در بخش های خاصی همچون education محبوبیت دارد. در هر دو صورت، استقرار و مدیریت VM ها ساده است و عمدتا درون خود هایپروایزر انجام می شود که بدین معناست که HPE SimpliVity شامل بسیاری از فرآیندها و مدیریت اختصاصی نمی شود که با عملکردهای کاربر در تداخل است. HPE SimpliVity همچنین از بسیاری شرکت های شخص ثالث همچون Veeam پشتیبانی می کند.
محیط های دمو متنوعی برای کار با HPE SimpliVity وجود دارد و در نتیجه استفاده از آن را ساده می سازد. HPE SimpliVity یکپارچگی جامعی را با VMware ارائه کرده است که به کاربران اجازه می دهد تا ذخیره ساز و قابلیت ها را از طریق یک vSphere Web Client مدیریت کنند. این امر شامل عملیات کاملی از VM از جمله بازیابی یک VM ،بازیابی فایل های خاص یا تقسیم نمودن نواحی بکاپ به ازای هر VM می شود.
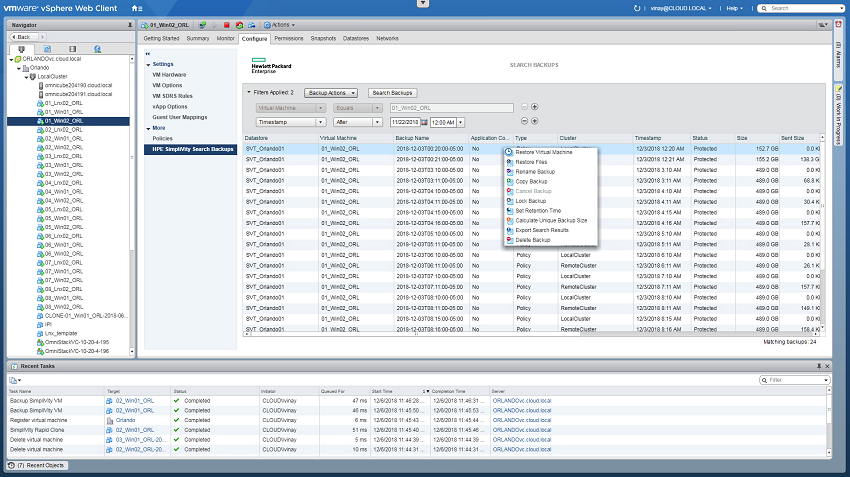
عملیات VMware
همچنین عملکردهای اصلی HPE SimpliVity درون کلاسترِ vSphere نهفته است که به کاربران اجازه ی مدیریت مواردی همچون ایجاد datastore جدید از ذخیره ساز موجود، مشاهده ظرفیت array ، مشاهده کارایی یا جستجو در سراسر بکاپ ها را می دهد.
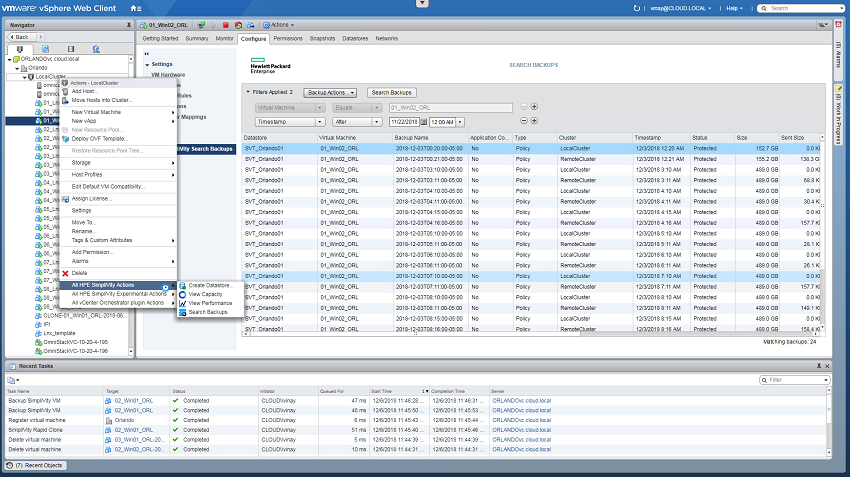
ایجاد datastore در VMware از طریق عملیات HPE SimpliVity
HPE SimpliVity HyperGuarantee مجموعه ای از ویژگی هایی است که data efficiency وprotection policy را در سراسر کلاستر تضمین می کند. همچنین تضمین کننده ی کانفیگ های ساده و fast recovery است. HPE SimpliVity علاوه بر این که یک سیستم HyperConverged Infrastructure است، همچنین برای data availability استفاده می شود. جهت فهم فوایدِ HPE SimpliVity در چگونگی برقراریِ availability ، باید چگونگیِ عملکرد نرم افزار آن را دریافت.
وجود Dedup pool های سراسری چیزی است که به پلتفرم اجازه خواهد داد که data efficient باشد. تنها بلوک های داده ی جدید به کلاسترهای دیگر برای replication فرستاده می شوند تا حجم فضای اشغال شده از ذخیره ساز را به حداقل برساند. این مسئله همچنین باعث خواهد شد که replication سریعتری برای داده های بکاپِ خود داشته باشد. این داده های کمتر، با سرعت بیشتری در فرآیند بکاپ منتقل می شوند، همچنین قادر خواهد بود که replicate داده را در سراسر لینک های شبکه ای که سرعت پایین تری دارند، انجام دهد. برخی ممکن است داده ها را بر روی لینک های ماهواره ای ارسال نمایند که عموما سرعتی پایین یا تاخیری بسیار زیاد برای مدیریت کردن دارند. برای افزایش سرعت انتقال داده تحت WAN ، سیستم HPE SimpliVity ردیابیِ بلوک های تغییر یافته یا replicate شده را کنار می گذارد. به جای آن یک الگوریتم و metadata را به کار می بندد تا تنها داده های منحصر به فردی را ارسال نماید که دریافت کننده پیش از این مشاهده نکرده است.
مدیریتِ سیاست های بکاپ از طریق vSphere به سادگی انجام می پذیرد.
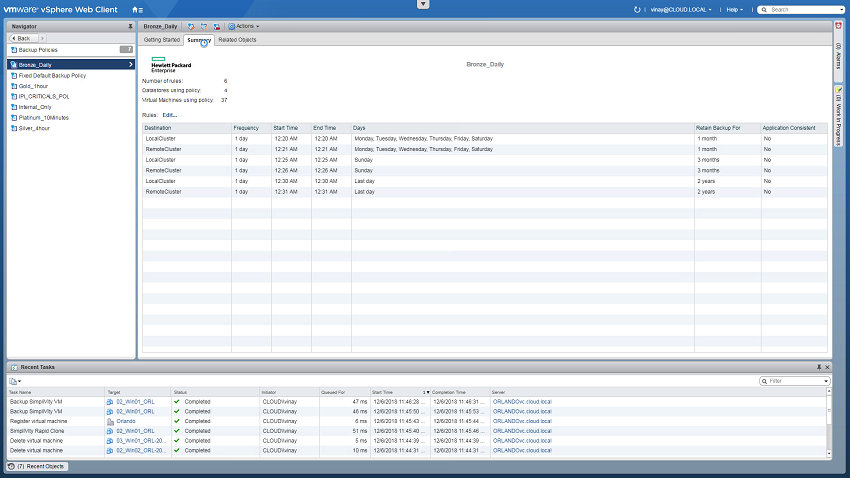
سیاست های بکاپ در VMware
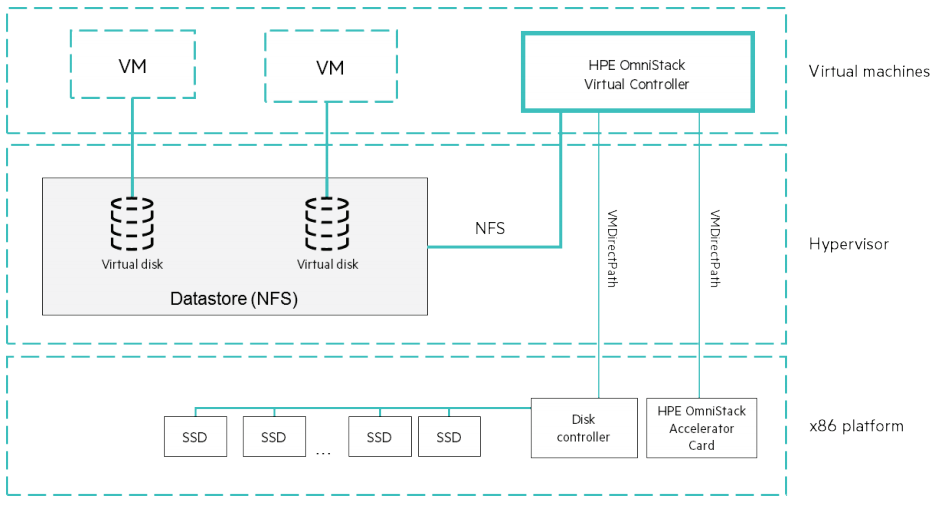
شمایی از HPE SimpliVity
RapidDR راهکاری است که برای مرتفع نمودنِ مسئله ی اصلی در هر سازمان، یعنی کاهش زمانِ downtime طراحی شده است. راهکار RapidDR از طریق خودکارسازی، روندِ off-site Data Recovery را تسهیل می کند و به آن سرعت می بخشد. این راهکار RPO (حداکثر مقدار مجاز برای data loss که سازمان می تواند بپذیرد) و RTO (حداکثر مدت زمانی که یک سازمان در اثر یک رویداد می تواند downtime را تحمل نماید) را از چندین روز یا چندین ساعت به چند دقیقه می کاهد. اولین گامی که HPE SimpliVity در این راستا بر می دارد، خودکارسازی فرآیندهای بازیابی است که شامل این خواهد شد که کدام VM ها روشن شده اند، تنظیمات آدرس IP و دیگر تنظیمات شبکه، مراکز منبع و اسکریپت های post-recovery . راه اندازیِ DR و اجرای آن به منظور صرفه جویی در زمان و هزینه انجام می گیرد. خودکارسازی منجر به بهبود سازگاری و کاهش خطرات می شود. کاربران می توانند طرح هایی برای DR ترسیم نمایند که آنها را در بهترین وضعیت ممکنی قرار دهد که در آن با مشکلات حقوقی و مالی مواجه نشوند.
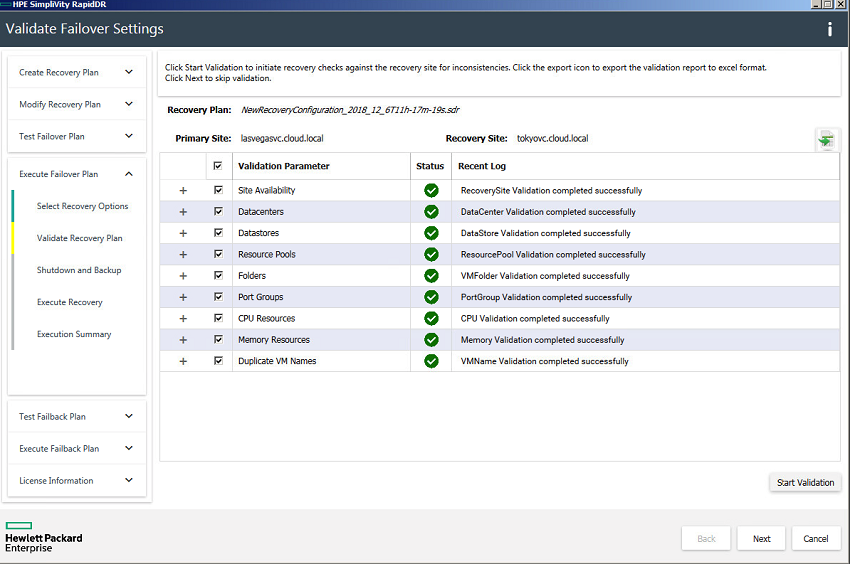
HPE SimpliVity RapidDR
نتیجه گیری:
یکی از ویژگی های اولیه این دستگاه، سهولت استفاده از آن و ادغامِ آن با محیط های VMware است. همچنین مجموعه ی کاملی از ویژگی های data availability و disaster recovery را پشتیبانی می کند. بیشتر دستگاه های HCI این نوع کارها را به برنامه های third party واگذار می کنند در حالی که HPE SimpliVity به خوبی آنها را ارائه می دهد.
HPE SimpliVity منحصرا بر روی سخت افزار HPE Proliant قرار دارد. در اجرای عملیات های سنگین ممکن است یک سرور نسبت به سروری دیگر از لحاظ مدیریتی یا دلایلی دیگر ترجیح داده شود، احتمال آن وجود دارد که HPE SimpliVity از این موقعیت ها بازنده بیرون بیاید. همچنین HPE SimpliVity هنوز تکنولوژی های ذخیره سازی نوظهور را پوشش نمی دهد. از همان آغاز تیم HPE SimpliVity به دنبال تسهیلِ عملیات مرتبط با IT بوده است و از این جنبه محصول موفق بوده است.
شبکه و تجهیزات شبکه...برچسب : HPE SimpliVity, نویسنده : شاهرخ urnetwork بازدید : 96
پروتکل NetFlow ابزاری نهفته در نرم افزار Cisco IOS است که عملکرد شبکه را توصیف می کند. برخورداری از visibility نسبت به اجزا و عملکردِ شبکه امری ضروری برای شاغلین IT به شمار می آید. اپراتورهای شبکه دریافته اند که برای پاسخگویی به نیازهای شبکه، باید به درک درستی از رفتار شبکه برسند. این رفتارها شامل موارد زیر می شوند:
- استفاده از شبکه و اپلیکیشن
- بهره وری شبکه و بهره برداری از منابع شبکه
- اثر تغییرات بر شبکه
- ناهنجاری های شبکه و آسیب پذیری های امنیتی
- مسائلِ بلند مدت
پروتکل NetFlow این نیازها را برآورده می سازد. محیطی را ایجاد می کند که ادمین به واسطه آن ابزارهایی را در اختیار خواهد داشت تا دریابد که چه کسی، چه چیزی، چه زمانی، کجا و چگونه ترافیک شبکه در جریان است. هنگامی که رفتار شبکه فهمیده شود، فرآیندهای کسب و کار بهبود خواهد یافت و تاریخچه ای از چگونگی بهره برداری از شبکه ارزیابی خواهد شد. این افزایش آگاهی، نقاطِ آسیب پذیر شبکه را کاهش می دهد و منجر به اجرای کاراترِ عملیات در شبکه می شود. بهبود در عملیات شبکه، هزینه ها را کاهش می دهد و بنابراین از طریق بهره برداریِ بهتر از زیرساخت های شبکه، بازده کسب و کار افزایش می یابد.
نظارت بر کاراییِ SNMP
در اغلب شبکه ها برای مانیتورِ پهنای باند از پروتکل SNMP استفاده می شود. اگرچه SNMP طراحی ظرفیت شبکه را ساده می سازد، اما برای توصیف الگوهای ترافیکی ضعیف است، الگوهایی که در فهمِ چگونگی پشتیبانی از کسب و کار ضروری اند. درک عمیقتر از چگونگی استفاده از پهنای باند، در شبکه های IP امروزی از اهمیت بسیار بالایی برخوردار است. استفاده از counter ها در SNMP مفید هستند اما فهم اینکه چه آدرس های IP مبدا و مقصدِ ترافیک هستند و چه اپلیکیشن هایی ترافیک را تولید می کنند، ارزش بسیاری خواهد داشت.
پروتکل NetFlow
توانایی توصیفِ ترافیک شبکه و تشخیص اینکه این ترافیک چگونه و از کجا در جریان است برای دسترس پذیری، کارایی و عیب یابی شبکه اهمیت بسیاری دارد. مانیتورینگ جریان های ترافیک شبکه برنامه ریزیِ دقیق تر برای ظرفیت شبکه را تسهیل می کند و تضمین خواهد نمود که منابع مورد استفاده اهداف سازمان ها را پوشش می دهند. به کارکنان IT در تعیین موارد به کارگیریِ QoS، بهینه سازی استفاده از منابع کمک می کند. همچنین نقشِ اساسی را در رابطه با امنیت شبکه برای تشخیص حملات DoS، worm ها و دیگر رویدادهای ناخوشایندِ شبکه ایفا می کند.
پروتکل NetFlow چگونه اطلاعات شبکه را در اختیار شما می گذارد؟
هر packet که توسط روتر یا سوییچ سیسکو ارسال می شود از لحاظ مجموعه ای از ویژگی ها در بسته IP ارزیابی می شود. این ویژگی ها هویت بسته IP یا به عبارتی اثر انگشت آنها هستند و تعیین خواهند نمود که بسته منحصر به فرد است یا مشابه با دیگر بسته ها.
IP Flow به مجموعه ای پنج تایی یا حداکثر هفت تایی از ویژگی های بسته IP بستگی دارد. ویژگی های بسته IP که مورد استفاده قرار می گیرد، عبارتند از:
- آدرس IP مبدا
- آدرس IP مقصد
- پورت مبدا
- پورت مقصد
- نوع پروتکل لایه 3
- Class of Service (راهی برای مدیریت ترافیک در شبکه است، از طریق گروه بندی انواع مشابهی از ترافیک با یکدیگر با هر نوع به عنوان class با سطح اولویت بر خدمات مختص بر خود رفتار می کند)
- Interface مرتبط با روتر یا سوییچ
همه بسته هایی که آدرس IP مبدا/مقصد، پورت مبدا/مقصد، protocol interface و CoS یکسانی دارند در یک flow دسته بندی می شوند و سپس بسته ها مورد بررسی قرار می گیرند. این روش کار در تعیین یک flow قابل ارتقاست چرا که حجم بالای اطلاعات شبکه درون پایگاه داده ای از اطلاعات NetFlow فشرده می شوند که به آن NetFlow Cache می گویند.
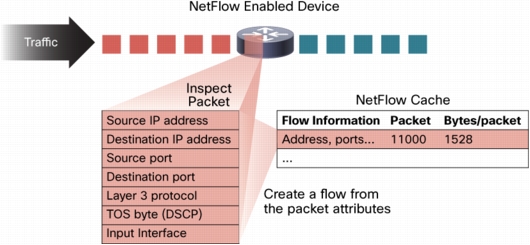
ایجاد یک flow در NetFlow Cache
اطلاعات flow برای فهم رفتار شبکه بسیار مفید است.
- آدرس مبدا در درک اینکه چه کسی ترافیک را ایجاد می کند، کمک می کند
- آدرس مقصد نشان می دهد که چه کسی ترافیک را دریافت کرده است
- پورتها توصیف کننده اپلیکیشن هایی هستند که از ترافیک شبکه استفاده می کنند
- CoS اولویت ترافیک ها را ارزیابی می کند
- اینترفیسِ دستگاه نحوه استفاده از ترافیک توسط دستگاه های شبکه را نشان می دهد
- بسته های شمارش شده نشان دهنده مقدار ترافیک هستند
اطلاعات دیگری که به یک flow افزوده می شوند، عبارتند از:
- Timestamp مرتبط با flow که به فهم مدتِ حیات یک flow کمک می کند، timestamp برای محاسبه بسته ها در هر ثانیه کاربرد دارد
- آدرس های IP در گام بعد، شامل مسیریابی BGP
- Subnet mask برای آدرس های مبدا و مقصد، به منظور محاسبه prefix
- TCP flag برای ارزیابی TCP handshake
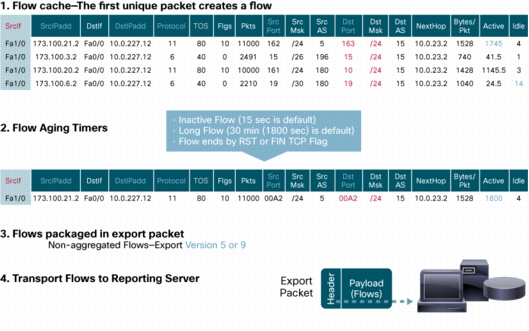
مثالی از داده های موجود در NetFlow Cache
چگونگی دستیابی به داده تولید شده توسط NetFlow
دو روش اولیه برای دسترسی به داده های NetFlow وجود دارد: استفاده از CLI یا بهره مندی از ابزار گزارشگیری. اگر بخواهید نگاهی لحظه ای بیاندازید به آنچه که در شبکه رخ می دهد، می توانید از CLI استفاده نمایید. NetFlow CLI کاربرد بسیاری برای عیب یابی دارد.
انتخاب دیگر، ارسال این اطلاعات به یک سرور گزارش گیری است یا به ابزارهایی که NetFlow collector نامیده می شوند. NetFlow collector وظایفی از جمله سرهم سازی و فهمِ flow های صادر شده و همچنین ترکیب یا ادغام آنها را بر عهده دارد. این وظایف به منظور تولید گزارش های ارزشمندی است که برای تحلیل امنیت و ترافیک استفاده می شوند. اطلاعات به صورت دوره ای به NetFlow collector صادر می شود. به طور کلی NetFlow cache همواره با flow ها در حال پر شدن است و نرم افزاری در روتر یا سوییچ در cache جستجو می کند تا flow هایی که خاتمه داده شده اند یا منقضی شده اند، بیابد و این flow ها به سرور NetFlow collector صادر می شوند. هنگامی که اتصال شبکه قطع شود، flow ها خاتمه می یابند (به طور مثال یک بسته ای که شامل TCP FIN flag می شود). گام های زیر برای پیاده سازی گزارش گیری از داده های NetFlow استفاده می شوند:
- NetFlow کانفیگ می شود تا flow ها را در NetFlow cache ثبت نماید
- NetFlow export کانفیگ می شود تا flow ها را به collector ارسال نماید
- Netflow cache به دنبال flow هایی می گردد که خاتمه یافته باشند و این flow ها به سرور NetFlow collector صادر می شوند
- به طور تقریبی بین 30 تا 50 flow با یکدیگر دسته بندی می شوند و معمولا در فرمت UDP به سرور NetFlow collector منتقل می شوند
- نرم افزار NetFlow collector گزارش هایی real-time یا بر مبنای تاریخ را از داده فراهم می کند
روتر یا سوییچ چگونه تخمین می زند که کدام flow ها به سرور NetFlow collector صادر شوند؟
هنگامی که یک flow برای مدتی غیرفعال باشد (یعنی هیچ بسته جدیدی برای flow دریافت نشده باشد) و یا برای مدت زمانی طولانی در حالت active قرار بگیرد و بیشتر از زمان سنجِ active به درازا بکشد (دانلود طولانی مدت FTP)، آماده برای صدور خواهد بود. همچنین هنگامی که یک TCP flag بر خاتمه یافتن یک flow دلالت کند (به طور مثال FIN، RST flag)، آن flow آماده صدور است. برای تعیین اینکه یک flow در وضعیت غیرفعال قرار دارد یا مدت زمان زیادی از حیاتش می گذرد، تایمرهایی وجود دارند. مقدار پیش فرض تایمر برای flow غیر فعال 15 ثانیه و برای flow فعال 30 دقیقه است. همه ی این تایمرها قابل کانفیگ هستند اما در اغلب موارد به جز بر روی پلتفرم سوییچ سیسکو catalyst 6500 از مقادیر پیش فرض استفاده می شود. Collector می تواند flow ها را ترکیب و ترافیک را تجمیع نماید. به طور مثال، دانلود FTP که بیشتر از زمان سنجِ active به درازا بکشد، ممکن است به چندین flow شکسته شود و collector می تواند این flow ها را ترکیب کند که نشان دهنده کل ترافیک FTP به سرور در زمان مشخصی از روز است.
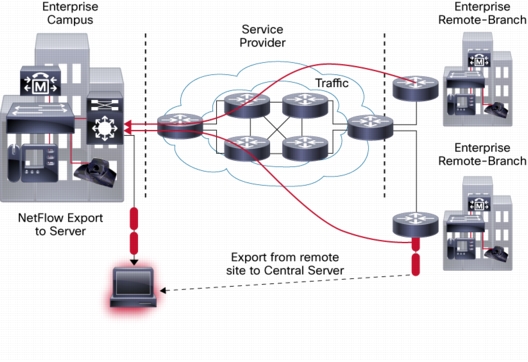
صدور flow ها به NetFlow Collector
فرمت داده های صادر شده به چه شکل است؟
فرمت های مختلفی برای بسته های export وجود دارد و اغلب به آنها export version می گویند. این version ها شامل فرمت های 5، 7 و 9 می شوند. رایج ترین فرمت برای NetFlow export نسخه 5 است اما نسخه 9 آخرین فرمت است و مزیت هایی برای تکنولوژی های کلیدی همچون امنیت، آنالیز ترافیک و multicast دارد.
سوییچ های سیسکو که از پروتکل NetFlow پشتیبانی می کنند عبارتند از:
- سوییچ سیسکو Catalyst 3650/3850
- سوییچ سیسکو Catalyst 3750-X از طریق ماژولِ سرویس 3K-X
- سوییچ سیسکو Catalyst 4500-X و 4500 از طریق Sup 7
- سوییچ سیسکو Catalyst 4900M ، 4948E-F
- سوییچ سیسکو 6500 از طریق SUP2T
- سوییچ سیسکو 6500 از طریق SUP720
- سوییچ سیسکو Catalyst 3560-CX و 2960-CX
- سوییچ سیسکو Nexus 1000
- سوییچ سیسکو Nexus 2000
- سوییچ سیسکو Nexus 5000 از طریق ماژول layer 3
- سوییچ سیسکو Nexus 7000 از طریق F Card
- سوییچ سیسکو Nexus 7000 از طریق M card
- سوییچ سیسکو Nexus 9000
- سوییچ سیسکو Nexus 1000v
روترهای سیسکو که از پروتکل NetFlow پشتیبانی می کنند:
- روتر سیسکو ISR G1 و G2
- روتر سیسکو سری 7600
- روتر سیسکو سری 10000
- روتر سیسکو سری XR12000/12000
- روتر سیسکو سری ASR 1000
- روتر سیسکو سری ASR 9000
- روتر سیسکو NCS 5000,6000
- روتر سیسکو CSR 1000v
خلاصه
پروتکل Netflow توسط سیسکو ارائه شده است، برای جمع آوری و ثبت تمامیِ ترافیک های IP گذرنده از یک روتر یا سوییچ سیسکو که قابلیت Netflow در آن فعال است. این پروتکل به شما اجازه می دهد تا ترافیک را از طریق برنامه Netflow Collector یا Analyzer جمع آوری و آنالیز نمایید.
به شما اجازه خواهد داد که واکاوی دقیقی از ترافیک شبکه خود داشته باشید تا به هنگام عیب یابی شبکه ای با سرعت پایین، دریابید مبدا و مقصد ترافیک ها کجاست. زمان لازم برای عیب یابی را کاهش می دهد و تهیه گزارش در رابطه با حجم بهره برداری از منابع شبکه را تسهیل می کند.به شما کمک می کند در فهم اینکه چه کسی در حال استفاده از شبکه است، مقصد ترافیک ها کجاست و اپلیکیشن ها چه حجمی از پهنای باند را مصرف می کنند.
سیسکو در ابتدا پروتکل NetFlow را برای محصولات خودش ایجاد نمود و اندکی پس از آن به استانداری تبدیل شد که بسیاری از سازندگان دیگر آن را بر روی محصولات خود پیاده سازی نمودند. این سازندگان شاملِ (Juniper(JFlow) ، 3Com، HP ، Ericsson(RFlow) ،Netgear(SFlow)، Huawei(NetStream و (Alcatel-Lucent(CFlow می شدند.
شبکه و تجهیزات شبکه...برچسب : پروتکل NetFlow, نویسنده : شاهرخ urnetwork بازدید : 140
IPv6 چیست؟
آدرس IP شناسه ای یکتا برای مشخص شدن یک device در یک شبکه می باشد. یکتا بودن آدرس IP بدین معناست که آدرس IP یک device داخل شبکه ای که در آن قرار دارد فقط به آن سیستم اختصاص دارد . تا زمانی که یک device آدرس IP نداشته باشد نمی تواند با device های دیگر ارتباط برقرار کند .
آدرس های IP به دو دسته تقسیم می شوند . دسته ی اول IPv4 می باشد که اکثر ما با آن برخورد داشته ایم و تا حدودی با آن آشنا هستیم. آدرس IP ورژن 4 یک آدرس 32 بیتی است که به صورت 4 عدد در مبنای ده که با نقطه از هم جدا شده اند، نمایش داده می شود (مانند : 192.168.1.1 ). این ورژن از IP به تعداد 2 به توان 32 آدرس را ارائه می کند. در حال حاضر بیش از 90 درصد آدرس ها در جهان ، IPv4 می باشد.
از آنجایی که استفاده از پروتکل TCP/IP در سال های اخیر بیش از حد انتظار بوده، در آدرس دهی IPv4 ، محدود هستیم و آدرس های IPv4 رو به اتمام است. این یکی از دلایلی است که TCP/IP یک ورژن جدید از آدرس های IP را طراحی کرد که با نام IPv6 شناخته می شود.
بعضی از مزیت هایی که IPv6 دارد :
- هزینه ی کمتر پردازشی : packet های IPv6 باز طراحی شده اند تا header های ساده تری را تولید و استفاده کنند که این موضوع فرایند پردازش packet ها توسط سیستم های فرستنده و گیرنده را بهبود می دهد.
- آدرس های IP بیشتر : IPv6 از ساختار آدرس دهی 128 بیتی استفاده می کند در حالی که IPv4 از ساختار آدرس دهی 32 بیتی استفاده می کند . این تعداد آدرس IP این اطمینان را می دهد که حتی بیشتر از آدرس های مورد نیاز در سال های آینده ، آدرس موجود است.
- Multicasting : در IPv6 از Multicasting به عنوان روش اصلی برقرار کردن ارتباط استفاده می شود. IPv6 بر خلاف IPv4 روش broadcast را ارائه نمی دهد. روش broadcast از پهنای باند شبکه به صورت غیر بهینه و نامناسب استفاده می کند.
- IPSec: پروتکل Inteet Protocol Security)IPSec) در درون IPv4 وجود نداشت اما IPv4 از آن پشتیبانی می کرد در حالی که IPv6 این پروتکل را به صورت built in در درون خود دارد و می تواند تمامی ارتباطات را رمز گذاری (encrypt) کند.
آدرس دهی در IPv6
در IPv6 تغییرات عمده ای نسبت به IPv4 وجود دارد. IPv4 از ساختار آدرس دهی 32 بیتی استفاده می کند در حالی که IPv6 از ساختار آدرس دهی 128 بیتی استفاده می کند. این تغییر می تواند 2 به توان 128 آدرس یکتا را ارائه دهد . این میزان آدرس IP، پیشرفت بسیار زیادی را نسبت به تعداد آدرس IP که IPv4 ارائه می کند(2 به توان 32) دارد.
آدرس IPv6 دیگر از 4 بخش 8 بیتی استفاده نمی کند. آدرس IPv6 به 8 قسمت 16 بیتی که هر قسمت ارقامی در مبنای 16 هستند و با (:) از هم جدا می شوند تقسیم میشود. مانند:
65b3:b834:45a3:0000:0000:762e:0270:5224
در مورد آدرس های IPv6 یک سری نکته هایی وجود دارد که باید آنها را بدانید:
- این آدرس ها نسبت به بزگی حروف حساس نیستند
- صفر های سمت چپ هر بخش را میتوان حذف کرد
- بخش هایی که پشت سر هم صفر هستند را میتوان به صورت (::) خلاصه نویسی کرد (روی هر آدرس فقط یک بار می توان این کار را کرد)
مثال: آدرس loopback در IPv6 به صورت زیر است :
0000:0000:0000:0000:0000:0000:0000:0001
از آنجایی که می توان صفرهای سمت چپ هر بخش را حذف کرد آدرس را بازنویسی می کنیم :
0:0:0:0:0:0:0:1
بعد از حذف کردن صفرهای سمت چپ ، می توانیم صفرهای پشت سر هم را نیز خلاصه نویسی کنیم :
1::
همانطور که اشاره کردیم ، فقط یک بار می توانیم صفرهای پشت سر هم را خلاصه نویسی کنیم ، علت این موضوع این است که اگر چند بار این خلاصه نویسی را روی بخش های مختلف آدرس انجام دهیم ، آدرس اصلی بعد از خلاصه نویسی مشخص نخواهد بود . به مثال زیر توجه کنید:
0000:0000:45a3:0000:0000:0000:0270:5224
در این مثال دو سری صفر های پشت سر هم وجود دارد . اگر هر دو را خلاصه نویسی کنیم به صورت زیر می شود :
45a3::270:5224::
در این حالت مشخص نیست که هر سری چه تعداد صفر پشت سر هم داشته ایم ، پس بهتر است که آن سری که تعداد صفر های بیشتری پشت سر هم دارد را خلاصه نویسی کنید.
0:0:45a3::270:5224
ساختار آدرس دهی در IPv6 به کلی تغییر کرده است ، به طوری که 3 نوع آدرس وجود دارد :
- Unicast: آدرس Unicast برای ارتباطات یک به یک استفاده می شود.
- Multicast: آدرس Multicast برای ارسال data به سیستم های مختلف در یک لحظه استفاده می شود. آدرس های Multicast با پیشوند FF01 شروع می شوند. برای مثال FF01::1 برای ارسال اطلاعات به تمام node ها در شبکه استفاده می شود ، در حالی که FF01::2 برای ارسال اطلاعات به تمام روترهای داخل شبکه استفاده می شود.
- Anycast: آدرس Anycast برای گروهی از سیستم ها که سرویسی را ارائه می کنند استفاده می شود.
توجه کنید که آدرس broadcast در IPv6 وجود ندارد.
آدرس های Unicast خود به سه دسته تقسیم می شود :
- Global unicast: آدرس های Global unicast ، آدرس های public در IPv6 میباشد و قابلیت مسیریابی در اینترنت دارد. این آدرس ها معادل آدرس های public در IPv4 می باشد.
- Site-local unicast: آدرس های Site-local unicast ، آدرس های private هستند و مشابه آدرس های private در IPv4 می باشند و فقط برای ارتباطات داخل شبکه ای استفاده می شوند. این آدرس ها همیشه با پیشوند FEC0 شروع می شوند.
- Link-local unicast: آدرس های Link-local unicast مشابه APIPA در IPv4 هستند و فقط می توانند برای ارتباط با سیستمی که به آن متصل هستند ، استفاده شوند. این آدرس ها با پیشوند FE80 شروع می شود.
نکته دیگری که باید به آن اشاره کنیم ، IPv6 ازClassless Inter-Domain Routing (CIDR) که در سال های اخیر متداول شده اند( برای تغییر بخش net ID روی IPv4 )،استفاده می کند.برای مثال آدرس 2001:0db8:a385::1/48 بدین معناست که 48 بیت اول آدرس تشکیل دهنده ی net ID است.
IPv6 به 3 بخش تقسیم می شود:
- Network ID: معمولا 48 بیت اول آدرس تشکیل دهنده ی net ID آن می باشد. در آدرس های global address ، net ID توسط ISP به سازمان شما اختصاص داده می شود.
- Subnet ID: این بخش از 16 بیت تشکیل شده و با استفاده از آنها می توانید شبکه ی IPv6 خود را به subnet های مختلف تقسیم کنید. برای مثال شبکه ای با net ID 2001:ab34:cd56 /48 می تواند به دو زیرشبکه 2001:ab34:cd56:0001/64 و 2001:ab34:cd56:0002/64 تقسیم شود.
- (Unique Identifier(EUI-64: نیمه ی دوم آدرس (64 بیت آخر) را unique identifier می نامند، این بخش مشابه host ID در IPv4 است (یک سیستم را در شبکه مشخص می کند). این بخش تشکیل می شود از مک آدرس آن سیستم (48 بیت)که به دو قسمت تقسیم شده و عبارت FFFE که میان آن دو قسمت قرار می گیرد.
Auto configuration
یکی از مزیت های IPv6 قابلیت auto configuration است ، که در آن سیستم یک آدرس IPv6 برای خود انتخاب می کند ، سپس با ارسال پیام neighbor solicitation به آن آدرس بررسی میکند که این آدرس در شبکه برای سیستم دیگری استفاده نشده باشد. اگر این آدرس توسط سیستم دیگری استفاده شده باشد ، به پیام جواب می دهد و سیستمی که قصد انتخاب آدرس را داشت متوجه می شود که از آن آدرس نمی تواند استفاده کند. قابل ذکر است احتمال اینکه یک آدرس به دو سیستم اختصاص داده شود خیلی کم است چون مک آدرس سیستم ها در آدرس دهی auto configuration استفاده می شود (مک آدرس یک آدرس یکتا است).
با توجه به تکنولوژی های پیش روی دنیای اطلاعات به ویژه IOT یا اینترنت اشیاء که به واسطه آن میتوان تعداد زیادی از اشیاء که در طول روز با آن ها سر و کار داریم (مانند سیستم های گرمایشی و سرمایشی، لوازم خانگی، ملزومات اداری و …)، که به صورت هوشمند کنترل می شوند را با یکدیگر در بستر اینترنت ارتباط خواهند داشت. این امر بدین معناست که به میلیاردها آدرس IP نیاز خواهیم داشت و ملزم به استفاده از IPv6 می باشیم .
شبکه و تجهیزات شبکه...برچسب : ipv6 چیست,ادرس دهی در ipv6,تفاوت ipv6 با ipv4, نویسنده : شاهرخ urnetwork بازدید : 94
Virtualization (مجازی سازی) فرایند ایجاد یک نسخه مجازی از چیزی مانند نرم افزار، سرور، استوریج و شبکهاست. این فرایند موثرترین راه برای کاهش هزینه های دنیای فناوری اطلاعات است در حالی که در تمام سطوح کارایی و بهره وری آن را افزایش می دهد.
مزایای Virtualization
مجازی سازی می تواند کارایی، انعطاف پذیری و مقیاس پذیری دنیای فناوری اطلاعات را افزایش دهد در حالی که هزینه ها را به طور قابل توجهی کاهش می دهد. جابجایی پویاتر بارهای پردازشی، عملکرد و دسترسی به منابع بهبود یافته و عملیات هایی که به صورت خودکار انجام می شوند. این ها همه مزایایی هستند که توسط مجازی سازی، مدیریت فناوری اطلاعات را ساده تر می کنند و هزینه های راه اندازی و نگهداری را کاهش می دهند. مزایای بیشتر مجازی سازی شامل موارد زیر می شود:
- کاهش هزینه های عملیاتی
- Downtime ها را کاهش داده و یا از بین برده
- افزایش بهره وری، کارایی و پاسخگویی دنیای IT
- آماده سازی سریعتر برنامه ها و منابع
- تداوم کسب و کار و بهبود بازیابی اطلاعات
- ساده سازی مدیریت دیتا سنتر
Virtualization چگونه کار می کند؟
با توجه به محدودیت های سرور های x86، سازمان ها باید سرورهای متعددی را تهیه کنند تا سرعتشان را در سطح نیازهای پردازشی و ذخیره سازی امروزه نگه دارند، در حالی که این سرورها از تمام ظرفیت های خود استفاده نمی کنند. نتیجه ی آن ناکارآمدی و صرف هزینه های زیاد است.
Virtualization از نرم افزار استفاده می کند تا عملکرد سخت افزار را شبیه سازی کند و یک سیستم کامپیوتر مجازی بسازد. این موضوع سازمان ها را قادر می سازد که در یک سرور بیش از یک سیستم کامپیوتر مجازی بسازند (که هر کدام می توانند سیستم عامل و نرم افزار های مختلفی را داشته باشند). مزایای آن عبارت اند از مقرون به صرفه بودن و بهره وری بهتر.
Virtual Machine
سیستم کامپیوتری مجازی که به نام ماشین مجازی (VM) شناخته می شود، یک محفظه ی نگهدارنده ی نرم افزار است که می تواند یک سیستم عامل و یا برنامه هایی را داخل خود داشته باشند. ماشین های مجازی کاملا از یک دیگر مستقل هستند. قرار دادن چندین VM در یک سیستم این اجازه را می دهد که سیستم عامل ها و برنامه های مختلفی را فقط در یک سرور فیزیکی و یا یک هاست اجرا کنیم.
یک لایه نازک از نرم افزار به نام “hypervisor” ماشین های مجازی را از هاستی که روی آن نصب شده اند جدا می کند. hypervisor متناسب با نیاز هر ماشین و به صورت پویا، منابع پردازشی را به ماشین ها اختصاص می دهد.
کلمات کلیدی مربوط به Virtual Machine
ماشین های مجازی مشخصات زیر را دارند که هر کدام فواید مختلفی را ارائه می کنند.
Partitioning
- اجرا کردن سیستم عامل های مختلف روی یک سرور
- تقسیم کردن منابع سیستم بین ماشین های مجازی
Isolation
- امنیت و بروز خطا برای هر ماشین مجازی در سطح سخت افزار ایزوله است
- حفظ عملکرد ماشین ها با کنترل پیشرفته ی منابع پردازشی
Encapsulation
- حالت کلی هر ماشین مجازی در فایل هایی ذخیره می شود
- ماشین های مجازی به سادگی جابجایی فایل ها، انتقال می یابند
Hardware Independence
- آماده سازی و جابجایی ماشین های مجازی به هر سروری
انواع مجازی سازی
مجازی سازی سرور
مجازی سازی سرور این امکان را می دهد که سیستم عامل های مختلفی را روی یک سرور به صورت ماشین های مجازی با بهره وری بالا، اجرا کنیم. فواید کلیدی آن به صورت زیر است:
- کارایی بهتر
- کاهش هزینه عملیاتی
- انجام سریع کار های سنگین
- بهبود عملکرد برنامه ها
- در دسترس بودن بالای سرور
- از بین بردن پیچیدگی سرور و جلوگیری از بی مصرف ماندن سرور
مجازی سازی شبکه
مجازی سازی شبکه ساخت دوباره ی یک شبکه فیزیکی به صورت کامل و منطقی است. مجازی سازی شبکه این امکان را می دهد که برنامه ها دقیقا به همان صورت که در شبکه ی فیزیکی اجرا می شوند در یک شبکه مجازی اجرا شوند که فواید عملیاتی بهتر و استقلال سخت افزاری موجود در مجازی سازی را به همراه دارد. مجازی سازی شبکه، دستگاه ها و سرویس های شبکه را به صورت منطقی ارائه می کند (مانند سوئیچ، روتر، فایروال و vpn)
مجازی سازی دسکتاپ
استقرار دسکتاپ به عنوان یک سرویس مدیریت شده مجازی سازی دسکتاپ این امکان را می دهد که سازمان های IT در مقابل تغییر نیاز ها و فرصت های در حال ظهور سریعتر پاسخ دهند. برنامه ها و Desktopهای مجازی را می توان به سرعت در دسترس کارکنان سازمان قرار داد در حالی که مکان این کارکنان میتواند در داخل سازمان و یا اینکه دور از سازمان باشد. این کارکنان حتی می توانند از ipad و تبلت های اندرویدی خود برای دسترسی به این برنامه ها و desktopها استفاده کنند.
مجازی سازی در مقابل CLOUD COMPUTING
اگرچه مجازی سازی و Cloud Computing هر دو تکنولوژی های فوق العاده ای هستند اما نمی توان آن ها را به جای هم نام برد و استفاده کرد. مجازی سازی یک راهکار نرم افزاری است که محیط محاسبات پردازشی را از زیرساخت های فیزیکی مستقل می کند، در حالی که Cloud Computing سرویسی است که با دریافت تقاضا منابع محاسباتی به اشتراک گذاشته (مانند نرم افزار یا اطلاعات) را از طریق اینترنت در دسترس دریافت کننده ی سرویس قرار می دهد. به عنوان یک راه حل تکمیلی، سازمان ها می توانند با مجازی سازی سرور های خود شروع کنند، سپس به سمت استفاده از Cloud Computing حرکت کنند تا کارایی بهتر و سرویس بهینه تری را داشته باشند.
برچسب : مجازی سازی,انواع مجازی سازی,مجازی سازی دسکتاپ,مجازی سازی سرور,مجازی سازی شبکه, نویسنده : شاهرخ urnetwork بازدید : 128
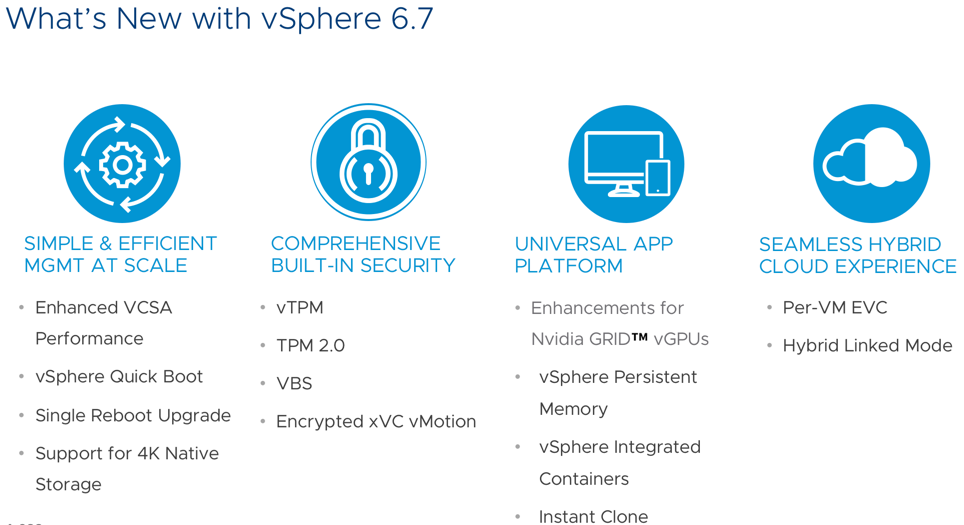
vSphere 6.7 معرفي شد ! و vCenter Server Appliance اكنون به صورت پيش فرض deploy ميشود . اين نسخه پر از پيشرفت هاي جديد براي vCenter Server Appliance در تمام زمينه ها است . اكنون مشتريان ابزارهاي بيشتري براي كمك به مانيتورينگ دارند. vSphere Client) HTML5) پر از جريان هاي كاري جديد و نزديك به ويژگي هاي آينده نگرانه است. معماري vCenter Server Appliance به سمت مدل پياده سازي ساده تر حركت مي كند. همچنين File-Based backup دروني كه با يك scheduler همراه است . و رابط گرافي كاربر vCenter Server Appliance كه از تم Clarity پشتيباني ميكند . اينها فقط بخشي از ويژگي هاي جديد در vCenter Server Appliance 6.7 هستند .اين مقاله به جزئيات بيشتري از پيشرفت هاي ذكر شده در بالا وارد خواهد شد.
Lifecycle
Install
يكي از تغييرات مهم در vCenter Server Appliance، ساده سازي معماري است . در گذشته تمام سرويس هاي vCenter Server در يك instance قرار داشت . اكنون ميتوانيم دقيقا همان كار را با vCenter Server Appliance 6.7 انجام دهيم . vCenter Server با Embedded PSC به همراه Enhanced Linked Mode ارائه ميشود. بياييد نگاهي به مزايايي كه اين مدل پياده سازي ارائه مي دهد بيندازيم:
- براي ايجاد high availability نيازي به load balancer نيست و به طور كامل از native vCenter Server High Availability پشتيباني ميكند .
- حذف SSO Site boundary ، پياده سازي را با انعطاف پذيري بيشتري همراه كرده است.
- پشتيباني از حداكثر مقياس vSphere
- ميتوانيد تا 15 دامنه براي استفاده از vSphere Single Sign-On اضافه كنيد
- تعداد گره ها را براي مديريت و نگهداري كاهش مي دهد
Migrate
vSphere 6.7 همچنين آخرين نسخه براي استفاده از vCenter Server براي ويندوز را داراست ، كه در گذشته نبود. مشتريان مي توانند با ابزار داخلي Migration Tool به vCenter Server Appliance مهاجرت كنند. در vSphere 6.7 مي توانيد نحوه وارد كردن داده هاي تاريخي و عملكرد را در هنگام Migrate انتخاب كنيم.
- Deploy & import all data
- Deploy & import data in the background
مشتريان همچنين زمان تخمين زده شده از مدت زماني كه طول ميكشد تا Migrate انجام شود را ميبينند . زمان تخمين زده شده بر اساس اندازه داده هاي تاريخي و عملكرد در محيط شما متفاوت است. در حالي كه مشتريان ميتوانند در زمان وارد كردن داده ها در پس زمينه عمليات را pause يا resume كنند . اين قابليت جديد در رابط مديريت vSphere Appliance موجود است. يكي ديگر از بهبود ها پشتيباني از پورت هاي custom در زمان عمليات Migrate است . مشترياني كه پورت پيش فرض Windows vCenter Server را تغيرداده اند ديگر مسدود نميشوند.

Upgrade
vSphere 6.7 فقط از upgrades يا migrations از vSphere 6.0 يا 6.5پشتيباني ميكند . vSphere 5.5 مسير مستقيم بروزرساني به vSphere 6.7 ندارد. مشترياني با vSphere 5.5 بايد ابتدا به vSphere 6.0 يا 6.5بروزرساني كنند و بعد به vSphere 6.7 بروزرساني انجام دهند . هم چنين vCenter Server 6.0 يا 6.5 كه هاست ESXi 5.5 دارند نميتوانند بروزرساني يا migrations انجام دهند ، تا زماني كه حداقل به نسخه ESXi 6.0 يا بالاتر بروز كنند .
يادآوري : vSphere 5.5 در تاريخ September 19, 2018. به پايان پشتيباني general ميرسد.
نظارت و مديريت
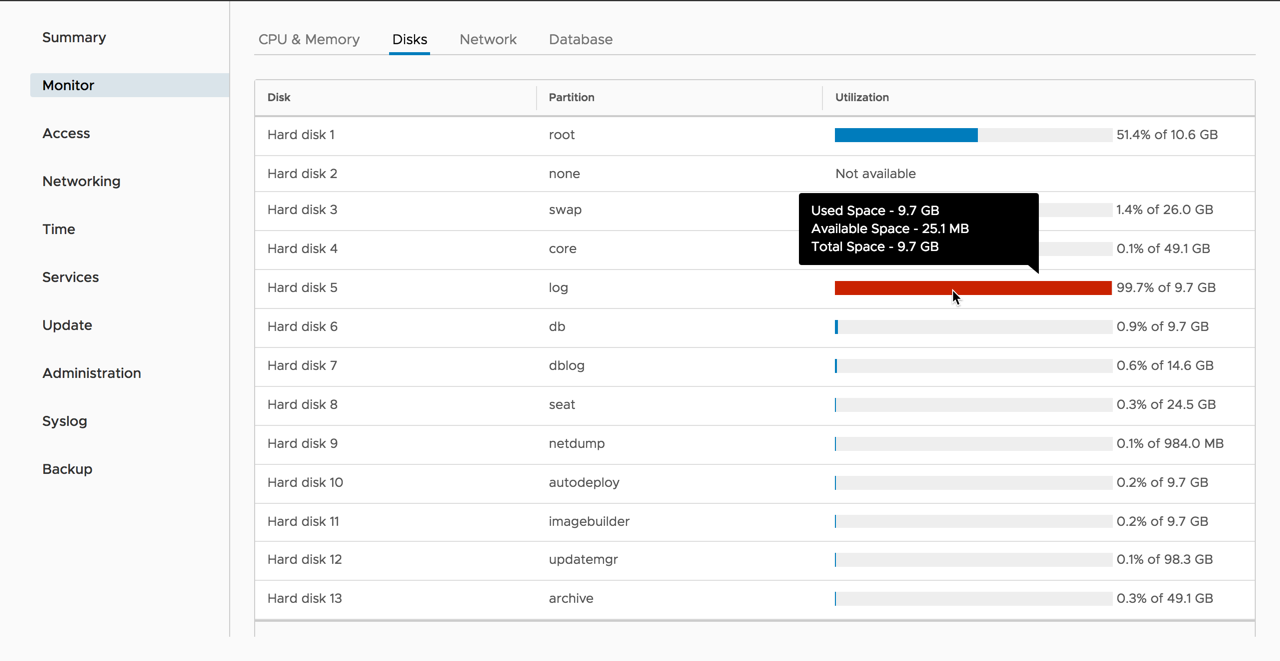
سرمايه گذاري بسياري جهت بهبود وضعيت Monitoring در vCenter صورت گرفته است. ما شروع اين بهبود را از VSphere 6.5 ديديم و در VSphere 6.7 شاهد چندين پيشرفت جديد نيز مي باشيم. بياييم به پنل مديريتي vSphere VAMI بر روي پورت 5480 متصل شويم. اولين چيزي كه مشاهده مي كنيم اين است كه VAMI به محيط كاربري Clarity آپديت شده است. ما همچنين مي بينيم كه در مقايسه با vSphere 6.5 تعدادي تب جديد در پنل سمت چپ قرار گرفته است. يك تب اختصاصي براي مانيتورينگ قرار داده شده است، كه در آن ما مي توانيم ميزان مصرف و وضعيت سي پي يو، رم، شبكه و Database ها را مشاهده نمائيم. بخش جديدي در تب مانيتورينگ تحت عنوان Disks قرار داده شده است. مشتريان مي توانند پارتيشن هر يك از ديسك هاي vCenter سرور، فضاي باقيمانده و مصرف شده را مشاهده نمايند.

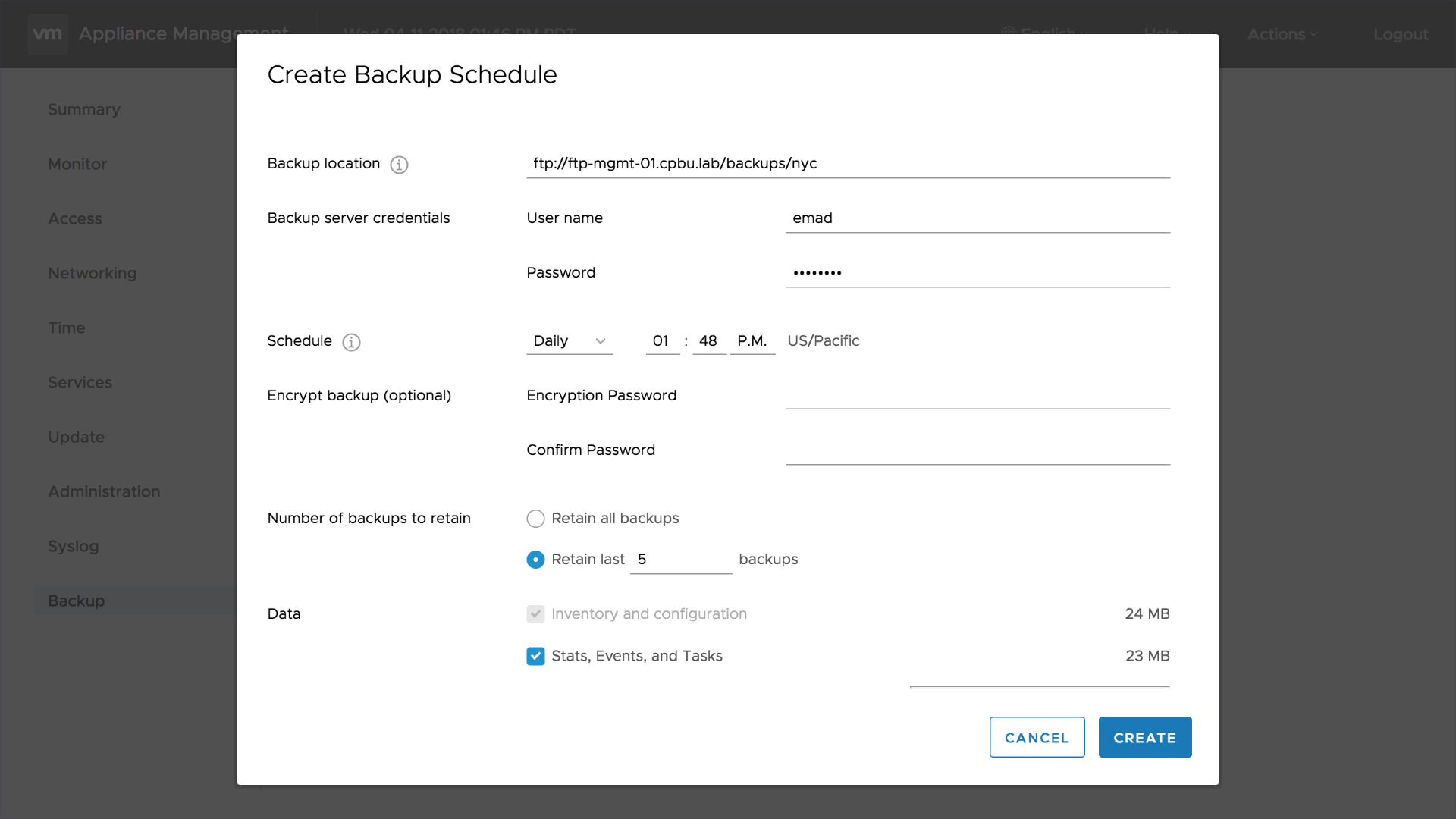
بكآپ هاي File-Based اولين بار در vSphere 6.5 در زيرمجموعه تب summary قرار گرفتند و اكنون تب مخصوص خود را دارند. اولين گزينه ي در دسترس در تب بكآپ تنظيم scheduler مي باشد. مشتريان مي توانند بكآپ هاي vCenter را برنامه ريزي زماني نموده و انتخاب نمايند كه چه تعداد بكاپ حفظ گردد. يك قسمت جديد ديگر در بكـاپ هاي File-Based ، Activities مي باشد. هنگام كه يك job بكآپ كامل مي شود اطلاعات با جزييات اين رويداد در قسمت Activity به عنوان گزارش قرار مي گيرد. ما نمي توانيم بدون در نظر گرفتن Restore كردن در مورد بكآپ صحبت كنيم. روند كاري Restore ، اكنون شامل مرورگر آرشيو بكآپ ها مي باشد. اين مرورگر تمام بكاپ هاي شما بدون نياز به دانستن مسير هاي بكآپ نشان مي دهد.
تب جديد ديگر Services مي باشد كه در VAMI قرار گرفته است. زماني درون vSphere Web Client بود و اكنون در VAMIبراي عيب يابي out of band هست . تمام سرويس هاي vCenter Server Appliance ، نوع راه اندازي، سلامت و وضعيت آنها در اينجا قابل مشاهده است . ما همچنين گزينه اي براي شروع، متوقف كردن و راه اندازي مجدد اين سرويس ها در صورت نياز داريم. در حالي كه تب هاي Syslog و Update در VAMI جديد نيستند ، اما در اين زمينه ها پيشرفت نيز وجود دارد. Syslog اكنون تا سه syslog forwarding targets پشتيباني ميكند. پيش از اين vSphere 6.5 فقط از يكي پشتيباني ميكرد . اكنون انعطاف پذيري بيشتري در پچ كردن و به روز رساني وجود دارد. از برگه Update، اكنون گزينه اي براي انتخاب اينكه كدام پچ يا به روز رساني اعمال شود وجود دارد. مشتريان همچنين اطلاعات بيشتري از جمله نوع ، سطح لزوم و همچنين در صورت نياز به راه اندازي مجدد را مشاهده ميكنند. با باز كردن پنجره نمايش پچ يا به روز رساني ، اطلاعات بيشتر در مورد آنچه كه شامل است نمايش داده خواهد شد و در نهايت ، اكنون مي توانيم پچ يا به روز رساني را از VAMI نصب واجرا كنيم. اين قابليت قبلا تنها از طريق CLI در دسترس بود.
(vSphere client(HTML5
از ويژگي هايي كه در vSphere 6.7 روي آن سرمايه گذاري قابل توجه اي شده است VSphere client ميباشد. VMware با معرفي vSphere 6.5 نسخه vSphere Client (HTML5) را معرفي كرد كه در vCenter server Application از قابليت هاي جزئي برخوردار بود. تيم فني vSphere به سختي بر روي آن كار مي كنند تا از ويژگي هاي بيشتري پشتيباني نمايد و بر اساس باز خورد مشتريان عملكرد و ويژگي آن بهبود چشم گيري يافته است. برخي از ويژگي هاي جديدي كه در نسخه vSphere client به روز شده شامل موارد زير است:
- vSphere Update Manager
- Content Library
- vSAN
- Storage Policies
- Host Profiles
- vDS Topology Diagram
- Licensing
بعضي از به روز رساني هايي كه در بالا ذكر شده داراي تمام ويژگي هاي عملكردي نيست . VMware به روز رساني هاي vSphere Client را ادامه خواهد داد تا با ارائه (patch/update) اين موارد بهبود يابد.
اكنون در منوي مديريت ، گزينه هاي PSC بين دو زبانه تقسيم مي شوند. Certificate management داراي برگه خاص خود است و تمام تنظيمات مديريتي ديگر زير برگه configuration هستند.
CLI Tools
CLI در vCenter Server Appliance 6.7 نيز داراي برخي از پيشرفت هاي جديدي است . اولين پيشرفت Repoint با استفاده cmsso-util است. در حالي كه اين يك ويژگي جديد نيست ، اين قابليت در vSphere 6.5 موجود نبود و در Vsphere 6.7 دوباره اجرايي شده است . ما در مورد vCenter Server Appliance كه به صورت مجزا با SSO Vsphere هست صحبت مي كنيم.
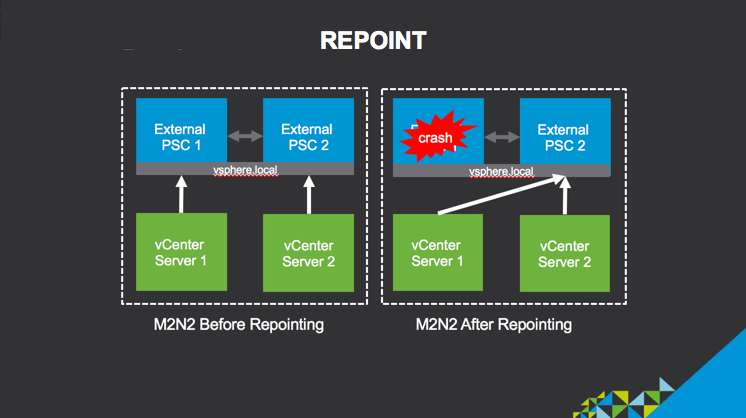
كاربران مي توانند vCenter Server Appliance خود را از طريق vSphere SSO domains ، ريپوينت كنند. قابليت Repoint فقط از exteal deployments كه vSphere 6.7 دارد پشتيباني ميكند . قابليت Repoint داخلي ويژگي pre-check دارد كه من ترجيح ميدهم استفاده نكنم ! ويژگي pre-check دو دامنه SSO را با هم مقايسه ميكند و ليست اختلافات آنها را در يك فايل JSON ذخيره ميكند. اين فرصتي است كه هر يك از اين اختلافات را قبل از اجراي domain repoint tool حل كنيد. ابزار repoint ميتواند لايسنس ها ، تگ ها ، دسته بندي ها و permissions ها را از يك دامنه vSphere SSO به ديگري منتقل كند .
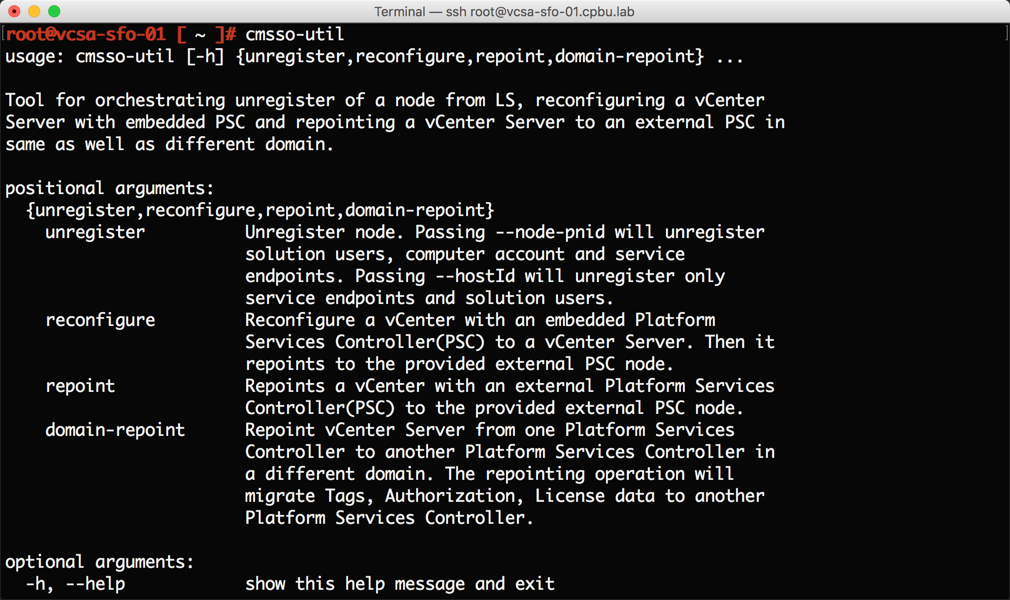
يكي ديگر از بهبود هاي CLI ، استفاده از cli installer ، براي مديريت lifecycle در vCenter Server Appliance است .
vCenter Server Appliance ISO معمولا با JSON template examples همراه است. اين JSON templates راهي براي اطمينان از سازگاري در طول نصب، ارتقاء و migrate است . معمولا ما بايد يك JSON template را از cli installer در همان زمان و به روش صحيح اجرا كنيم . اين پياده سازي دستي per-node در حال حاضر با عمليات دسته اي ، از گذشته باقي مانده است. به عمليات دسته اي چندين JSON templates مي تواند به طور متوالي از يك دايركتوري بدون مداخله اجرا شود. براي تاييد الگوها در دايركتوري كه شامل توالي است از گزينه pre-checks استفاده كنيد.

جمع بندي
خب ، vCenter Server Appliance 6.7 اكنون استاندارد جديدي براي اجراي vCenter Server است . ما سعي خواهيم كرد چند مورد از ويژگي هاي برجسته اين نخسه را بررسي كنيم .
شبکه و تجهیزات شبکه...برچسب : مجازی سازی,vcsa چیست,vcenter server appliance چیست,کاربرد vcenter, نویسنده : شاهرخ urnetwork بازدید : 184
Spanning Tree Protocol
سوئیچ های سیسکو با استفاده از پروتکل STP، از به وجود آمدن loop در شبکه جلوگیری می کنند. در یک LAN که دارای مسیر های redundant می باشد، اگر پروتکل STP فعال نباشد، باعث به وجود آمدن یک loop نامحدود در شبکه می شود. اگر در همان LAN پروتکل STP را فعال کنید، سوئیچ ها برخی از پورت ها را بلاک می کنند و اجازه نمی دهند اطلاعات از آن پورت ها عبور کنند.
پروتکل STP با توجه به دو معیار پورت ها را برای بلاک کردن انتخاب می کند:
• تمامی deviceهای موجود در LAN بتوانند با هم ارتباط برقرار کنند. درواقع STP تعداد پورت های کمی را بلاک می کند تا LAN به چند بخش که نمی توانند با هم ارتباط برقرار کنند، تقسیم نشود.
• Frame ها بعد از مدتی drop می شوند و به طور نامحدود در loop قرار نمی گیرند.
پروتکل STP تعادلی را در شبکه به وجود می آورد بطوریکه frame ها به هر کدام از device ها که لازم باشد می رسند بدون اینکه مشکلات loop به وجود آید.
پروتکل STP با چک کردن هر interface قبل از اینکه از طریق آن اطلاعات ارسال کند، از به وجود آمدن loop جلوگیری می کند. در این روند چک کردن اگر آن پورت داخل VLAN خود در وضعیت STP forwarding باشد، از آن پورت در حالت عادی استفاده می کند، اما اگر در وضعیت STP blocking باشد، ترافیک تمام کاربران را بلاک می کند و هیچ ترافیکی در آن VLAN را از آن پورت عبور نمی دهد.
توجه کنید که وضعیت STP یک پورت، اطلاعات دیگر مربوط به پورت را تغییر نمی دهد. برای مثال با تغییر وضعیت خود تغییری در وضعیت trunk/access و connected/notconnect ایجاد نمی کند. وضعیت STP یک مقدار جدا از وضعیت های قبلی دارد و اگر در حالت بلاک باشد پورت را از پایه غیر فعال می کند.
نیاز به پروتکل STP
پروتکل STP از وقوع سه مشکل رایج در LANهای Etheet جلوگیری می کند. در نبود پروتکل STP ، بعضی از frame های Etheet برای مدت زیادی (ساعت ها، روز ها و حتی برای همیشه اگر deviceهای LAN و لینک ها از کار نیوفتند) در یک loop داخل شبکه قرار می گیرند. سوئیچ های سیسکو به طور پیش فرض پروتکل STP را اجرا می کنند. توصیه می کنیم پروتکل STP را تا زمانی که تسلط کامل به آن ندارید، غیر فعال نکنید.
اگر یک frame درloop قرار بگیرد Broadcast storm به وجود می آید. Broadcast storm زمانی به وجود می آید که هر نوعی از frameهای Etheet (مانند multicast frame،broadcast frame و unicast frameهایی که مقصدشان مشخص نیست) در loop بی نهایت داخل LAN قرار بگیرند. Broadcast stormها می توانند لینک های شبکه را با کپی های به وجود آمده از یک frame اشباع کنند و باعث از بین رفتن frameهای مفید شوند، و نیز با توجه به بار پردازشی مورد نیاز برای پردازش broadcast frameها، تاثیر قابل ملاحظه ای روی عملکرد deviceهای کاربران دارند.
تصویر 1-2 یک مثال ساده از Broadcast storm را نشان می دهد که در آن سیستمی که Bob نام دارد یک broadcast frame ارسال می کند. خط چین ها نحوه ارسال frameها توسط سوئیچ ها را در نبود STP نمایش می دهند.
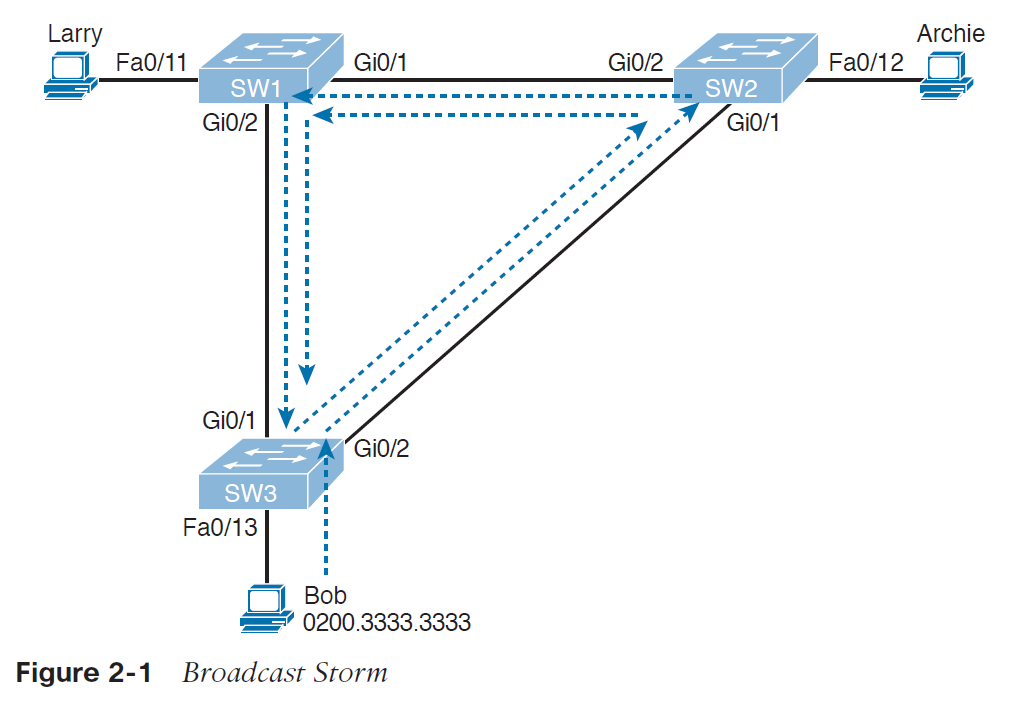
در تصویر 1-2، frameها در جهت های مختلفی می چرخند، برای ساده تر شدن مثال فقط در یک جهت آنها را نمایش داده ایم.
در مفاهیم سوئیچ، سوئیچ ها در ارسال کردن broadcast farmeها، frameها را به تمام پورت ها به جز پورت فرستنده آن frame، ارسال می کنند. در تصویر 1-2، سوئیچ SW3، frame را به سوئیچ SW2 ارسال می کند، سوئیچ SW2 آن را برای سوئیچ SW1 ارسال می کند، سوئیچ SW1 نیز آن را برای SW3 ارسال می کند و به همین ترتیب این frame به سوئیچ SW2 ارسال می شود و داخل یک loop می چرخد.
زمانی که یک Broadcast storm اتفاق می افتد، frame ها مانند مثال بالا به چرخیدن ادامه می دهند تا زمانی که تغییراتی به وجود آید (شخصی یکی از پورت ها را خاموش کند، سوئیچ را reload کند یا کاری کند که loop از بین برود).
Broadcast storm همچنین باعث به وجود آمدن مشکل نا محسوسی به نام MAC table instability یا ناپیوستگی جدول مک می شود. MAC table instability بدین معنا است که جدول مک آدرس پیوسته در حال تغییر کردن می باشد، و علت آن این است کهframe هایی با مک آدرس یکسان از پورت های مختلفی وارد سوئیچ ها می شوند. به مثال زیر توجه کنید:
در تصویر 1-2 در ابتدا سوئیچ SW3 مک آدرس باب را که از طریق پورت Fa0/13 وارد سوئیچ شده، به جدول مک آدرس خود اضافه می کند:
0200.3333.3333 Fa0/13 VLAN 1
حالا فرایند switch leaing را در نظر بگیرید در زمانی که frame در حال چرخش از سوئیچSW3 به سوئیچ SW2 ، سپس به سوئیچ SW1 و بعد از آن از طریق پورت G0/1 وارد سوئیچ SW3 می شود. سوئیچ SW3 می بیند که مک آدرس مبداء 0200.3333.3333 می باشد و از پورت G0/1 وارد سوئیچ شده است، جدول مک آدرس خود را به روز می کند:
0200.3333.3333 G0/1 VLAN 1
در این مورد سوئیچ SW3 هم دیگر نمی تواند به درستی frameها را به مک آدرس باب برساند. اگر در این حالت یک frame (خارج از frameهایی که در داخل loop افتاده اند) به سوئیچ SW3 برسد که مقصد آن باب باشد، سوئیچ SW3 اشتباها frame را روی پورت G0/1 به سوئیچ SW1 ارسال می کند، که این موضوع ترافیک زیادی را به وجود می آورد.
سومین مشکلی که Frame های در حال چرخش در یک broadcast storm ایجاد می کنند این است که کپی های مختلفی از یک frame به دست گیرنده می رسد. در تصویر 1-2 فرض کنید که باب یک frame را برای لاری ارسال کند در حالی که هیچ کدام از سوئیچ ها مک آدرس لاری را نمی دانند. سوئیچ ها frameها را به صورت unicast هایی که مک آدرس مقصدشان مشخص نیست، ارسال می کنند. زمانی که باب یک frame که مک آدرس مقصدش لاری است را ارسال می کند، سوئیچSW3 یک کپی از آن را به سوئیچ های SW1 و SW2 ارسال می کند. سوئیچ های SW1 و SW2 نیز frame را broadcast می کنند، این کپی ها باعث می شود که آن frame در داخل یک loop قرار گیرد. سوئیچ SW1 همچنین یک کپی از frame را به پورت Fa0/11 برای لاری ارسال می کند. در نتیجه لاری کپی های مختلفی از آن frame را دریافت می کند، که می تواند باعث از کار افتادن برنامه ای در سیستم لاری و یا مشکلات شبکه ای شود.
جدول زیر خلاصه ای از سه مشکل اساسی در شبکه ای که دارای redundancy است و STP در آن اجرا نمی شود را نشان می دهد:
پروتکل (STP (IEEE 802.1D دقیقا چه کار می کند؟
پروتکلSTP با قرار دادن هر یک از پورت های سوئیچ در وضعیت های forwarding و blocking از به وجود آمدن loop جلوگیری می کند. پورت هایی که در وضعیت forwarding هستند به صورت عادی فعالیت می کنند، frameها را ارسال و دریافت می کنند. اما پورت هایی که در وضعیت blocking قرار دارند به جز پیام های مربوط به پروتکل STP (و برخی دیگر از پیام هایی که برای پروتکل ها استفاده می شوند) ، هیچ frame دیگری را پردازش نمی کنند. این پورت ها frameهای کاربران را ارسال نمی کنند، مک آدرس frameهای ورودی را ذخیره نمی کنند و frameهای دریافتی از کاربران را نیز پردازش نمی کنند.
تصویر 2-2 راه حل استفاده از پروتکل STP (قرار دادن یکی از پورت های سوئیچ SW3 در وضعیت blocking) در مثال پیشین را نمایش می دهد:
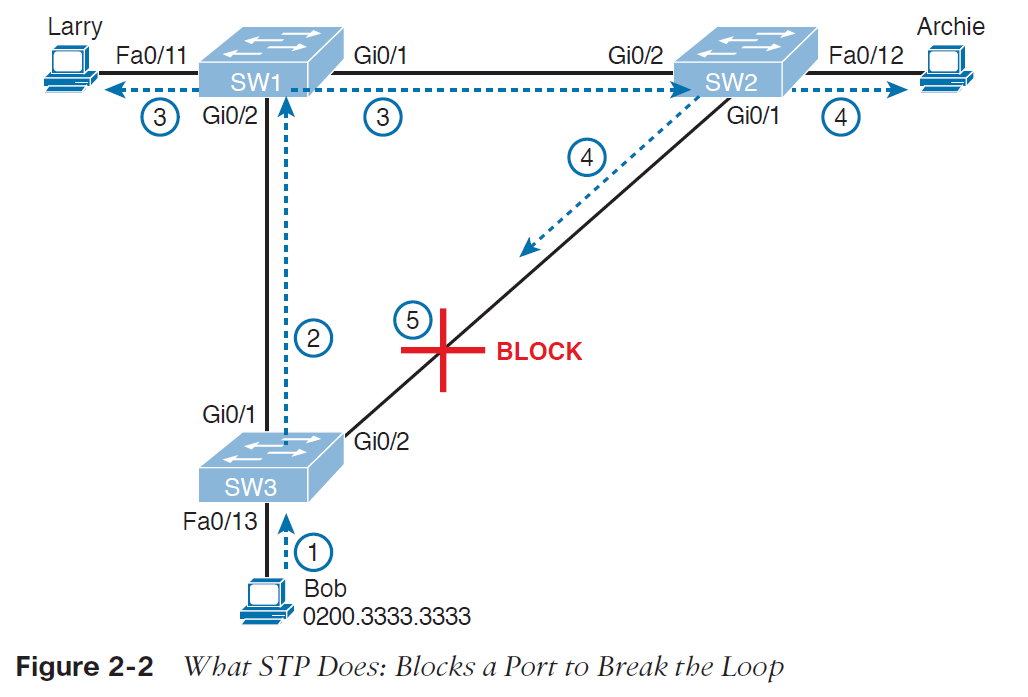
همانطور که در مراحل زیر نشان داده شده، زمانی که باب یک broadcast را ارسال می کند، دیگر loop به وجود نمی آید:
• مرحله اول: باب frame را به سوئیچ SW3 ارسال می کند.
• مرحله دوم: سوئیچ SW3 این frame را فقط به سوئیچ SW1 ارسال می کند، دیگر به سوئیچ SW2 ارسال نمی شود چون پورت G0/2 در وضعیت blocking قرار دارد.
• مرحله سوم: سوئیچ SW1 این frame را روی پورت های Fa0/12 و G0/1 ارسال می کند.
• مرحله چهارم: سوئیچ SW2 این frame را روی پورت های Fa0/12 و G0/1 ارسال می کند.
• مرحله پنجم: سوئیچ SW3 به صورت فیزیکی یک frame را دریافت می کند، اما frame دریافتی از SW2 را به دلیل اینکه پورت G0/2 در سوئیچ SW3 در وضعیت blocking قرار دارد، نادیده می گیرد.
با استفاده از توپولوژی STP در تصویر 2-2، سوئیچ ها از لینک موجود بین SW2 و SW3 برای انتقال ترافیک استفاده نمی کنند. با این حال، اگر لینک بین SW3 و SW1 دچار مشکل شود، پروتکل STP پورت G0/2 را از وضعیت blocking به وضعیت forwarding تغییر می دهد و سوئیچ ها می توانند از آن لینکredundant استفاده کنند. در این موقعیت ها پروتکل STP با انجام فرایند هایی متوجه تغییرات در توپولوژی شبکه می شود و تشخیص می دهد که پورت ها نیاز به تغییر در وضعیتشان دارند و وضعیت آن ها را تغییر می دهد.
سوالاتی که احتمالا زهن شما را نیز مشغول کرده: پروتکل STP چگونه پورت ها را برای تغییر وضعیت انتخاب می کند و چرا این کار را می کند؟ چگونه وضعیت blocking را برای بهره مندی از مزایای لینک های redundant، به وضعیت forwarding تغییر می دهد؟ در ادامه به این سوالات پاسخ خواهیم داد.
پروتکل STP چگونه کار می کند؟
الگوریتم STP یک درخت پوشا (spanning tree) از پورت هایی که frameها را ارسال می کنند تشکیل می دهد. این ساختار درختی، مسیرهایی را برای رسیدن لینک های etheet به هم مشخص می کند. (مانند پیمودن یک درخت واقعی که از ریشه درخت شروع می شود و تا برگ ها ادامه دارد)
توجه: STP قبل از اینکه در سوئیچ های LAN استفاده شود، در Etheet bridgeها به کار رفته بود.
STP از فرایندی که بعضا spanning-tree algorithm)STA) نامیده می شود، استفاده می کند که در آن پورت هایی که باید در وضعیت forwarding قرار بگیرند را انتخاب می کند. STP پورت هایی که برای forwarding انتخاب نشدند را در وضعیت blocking قرار می دهد. در واقع پروتکل STP پورت هایی که در ارسال کردن اطلاعات باید فعال باشند را انتخاب می کند و پورت های باقی مانده را در وضعیت blocking قرار می دهد.
پروتکل STP برای قرار دادن پورت ها در حالت forwarding از سه مرحله استفاده می کند:
• پروتکل STP یک سوئیچ را به عنوان root انتخاب می کند و تمام پورت های فعال در آن سوئیچ را در وضعیت forwarding قرار می دهد.
• در هر کدام از سوئیچ های nonroot (همه ی سوئیچ ها به جز root)، پورتی که کمترین هزینه را برای رسیدن به سوئیچ root دارد (root cost)، به عنوان root port(RP) انتخاب می کند و آن ها را در وضعیت forwarding قرار می دهد.
• تعداد زیادی سوئیچ می توانند به یک بخش از Etheet متصل شوند، اما در شبکه های مدرن، معمولا دو سوئیچ به هر لینک (بخش) متصل می شوند. در بین سوئیچ هایی که به یک لینک مشترک متصل هستند، پورت سوئیچی که root cost کمتری دارد در وضعیت forwarding قرار می گیرد. این سوئیچ ها را designated switch می نامند و پورت هایی که در وضعیت forwarding قرار گرفته را designated port)DP) می نامند.
باقی پورت ها در وضعیت blocking قرار می گیرند.
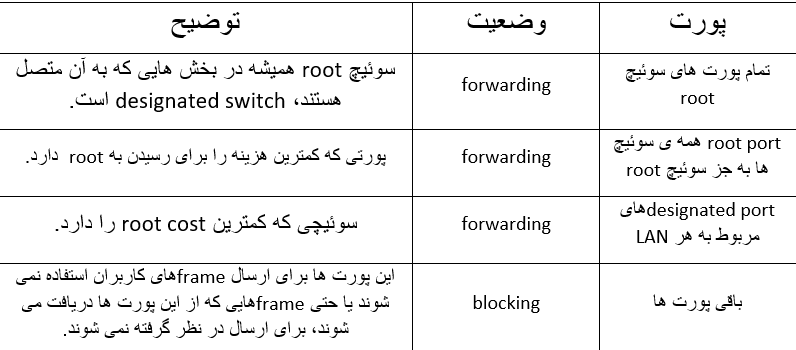
خلاصه ای از علت قرار گرفتن پورت ها در وضعیت های blocking و forwarding توسط پورتکل STP
Bridge و Hello BPDU
فرایند STA با انتخاب یک سوئیچ به عنوان root شروع می شود. برای اینکه روند انتخاب را بهتر متوجه شوید، شما باید با مفهوم پیام هایی که بین سوئیچ ها تبادل می شود به خوبی آشنا شوید و با فرمت شناساگری که برای شناسایی هر سوئیچ استفاده می شود آشنا باشید.
(STP bridge ID (BID یک مقدار 8 بایتی برای شناسایی هر سوئیچ می باشد. Bridge ID به دو بخش 2 بایتی که مشخص کننده اولویت و حق تقدم است و 6 بایتی که system ID نامیده می شود و همان مک آدرس هر سوئیچ است، تقسیم می شود. استفاده از مک آدرس این اطمینان را می دهد که bridge ID هر سوئیچ یکتا خواهد بود.
پیام هایی که برای تبادل اطلاعات مربوط به پروتکل STP بین سوئیچ ها استفاده می شود، bridge protocol data units )BPDU) نام دارد. رایج ترین BPDU ، که hello BPDU نام دارد، تعدادی از اطلاعات که شامل BID سوئیچ ها نیز می شود را لیست می کند و ارسال می کند. با استفاده از BID درج شده روی هر پیام، سوئیچ ها می توانند تشخیص دهند که هر پیام Hello BPDU از طرف کدام سوئیچ است.
جدول زیر اطلاعات کلیدی مربوط به Hello BPDU را نشان می دهد:
انتخاب سوئیچ root
سوئیچ ها با استفاده از BIDهای موجود در پیام های BPDU، سوئیچ root را انتخاب می کنند. سوئیچی که عدد BID آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب می شود. با توجه به اینکه بخش اول عدد BID مقدار اولویت می باشد، سوئیچی که مقدار اولویت پایین تری داشته باشد به عنوان سوئیچ root انتخاب می شود. برای مثال اگر سوئیچ های اول و دوم به ترتیب دارای اولویت های 4096 و 8192 باشند، بدون در نظر گرفتن مک آدرس سوئیچ ها که در به وجود آمدن BID هر سوئیچ موثر است، سوئیچ اول به عنوان سوئیچ root انتخاب خواهد شد.
اگر مقدار اولویت دو سوئیچ برابر شد، سوئیچی که مک آدرس آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب می شود. در این حالت به علت یکتا بودن مک آدرس، حتما یک سوئیچ انتخاب خواهد شد. پس اگر مقدار اولویت دو سوئیچ برابر باشد و مک آدرس آنها 0200.0000.0000 و 0911.1111.1111 باشد، سوئیچی که دارای مک آدرس 0200.0000.0000 است، به عنوان سوئیچ root انتخاب می شود.
مقدار اولویت مضربی از 4096 است و به صورت پیش فرض برای همه ی سوئیچ ها مقدار 32768 را دارد. از آنجایی که مک آدرس سوئیچ ها معیار مناسبی برای انتخاب سوئیچ root نمی باشد بهتر است به صورت دستی مقدار اولویت را تغییر دهیم تا سوئیچی که می خواهیم به عنوان سوئیچ root انتخاب شود.
در فرایند انتخاب سوئیچ root، سوئیچ ها از طریق فرستادن پیام های Hello BPDU که BID خود را در این پیام ها به عنوان root BID قرار داده اند، سعی می کنند خود را به عنوان سوئیچ root به سوئیچ های مجاور خود معرفی کنند. اگر یک سوئیچ پیامی را دریافت کند که BID کمتری نسبت به BID خودش داشته باشد، آن سوئیچ دیگر خود را به عنوان سوئیچ root معرفی نمی کند، به جای آن شروع به ارسال پیام دریافتی که دارای BID بهتری است می کند (مانند رقابت های انتخاباتی که یک نامزد به نفع نامزد هم حزبش که موقعیت بهتری دارد، از رقابت در انتخابات خارج می شود). در نهایت تمامی سوئیچ ها به یک نظر نهایی می رسند که کدام سوئیچ BID کمتری دارد و همه آن سوئیچ را به عنوان سوئیچ root انتخاب می کنند.
توجه : در مقایسه دو پیام Hello با هم، پیامی که BID کمتری دارد، superior Hello و پیامی که BID بیشتری دارد، inferior Hello نام دارد.
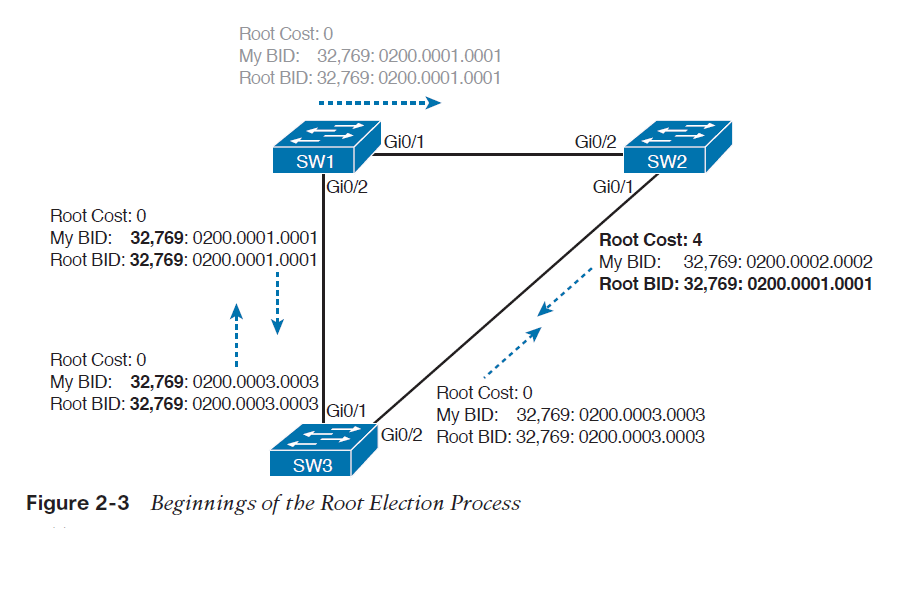
تصویر 3-2 آغاز فرایند انتخاب سوئیچ root را نشان می دهد، در ابتدای این فرایند SW1 همانند باقی سوئیچ ها خود را به عنوان سوئیچ root معرفی می کند. SW2 پس از دریافت Hello مربوط به SW1 متوجه می شود که SW1 شرایط بهتری را برای root بودن دارد، پس شروع به ارسال Hello دریافتی از SW1 می کند. در این حالت سوئیچ SW1 خود را به عنوان root معرفی می کند و SW2 نیز با آن موافقت می کند اما سوئیچ SW3 هنوز سعی می کند که خود را به عنوان سوئیچ root معرفی کند و Hello BPDUهای خود را ارسال می کند.
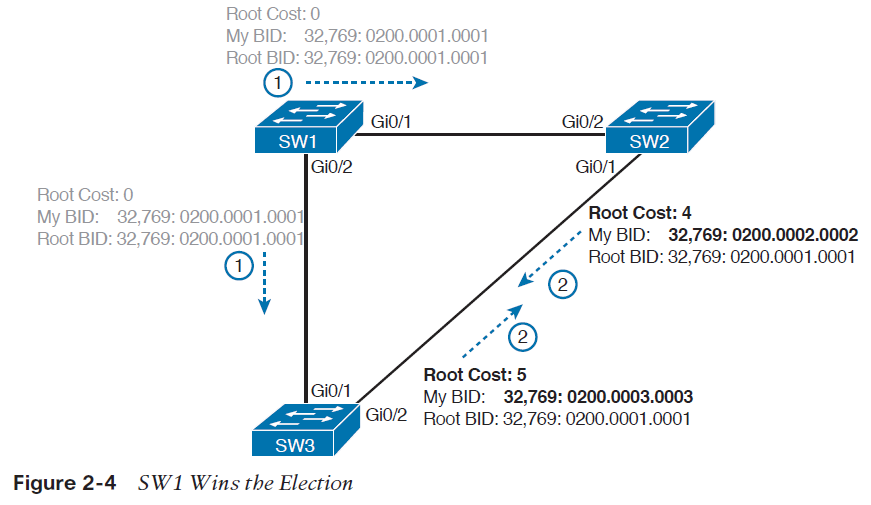
دو نامزد هنوز باقی ماندند:SW1 و SW3. از آنجایی که SW1 مقدار BID کمتری دارد، SW3 پس از دریافت BPDU مربوط به SW1، SW1 را به عنوان سوئیچ root می پذیرد و به جای BPDU خود، BPDU دریافتی از SW1 را به سوئیچ های مجاور ارسال می کند.
پس از اینکه فرایند انتخاب تکمیل شد، فقط سوئیچ root به تولید پیام های Hello BPDU ادامه می دهد. سوئیچ های دیگر این پیام ها را دریافت می کنند و BID فرستنده و root costرا تغییر می دهند و به باقی پورت ها ارسال می کنند. در تصویر 4-2، در قدم اول سوئیچ SW1 پیام های Hello را ارسال می کند، در قدم دوم سوئیچ های SW2 و SW3 به صورت مستقل تغییرات را روی پیام های دریافتی اعمال می کنند و آن ها را روی پورت های خود ارسال می کنند.
برای اینکه بخواهیم مقایسه BID را خلاصه کنیم، BID را به بخش های تشکیل دهنده ان تقسیم می کنیم، سپس به صورت زیر مقایسه می کنیم:
• اولویتی که کمترین مقدار را دارد
• اگر مقدار اولویت آن ها برابر باشد، سوئیچی که مک ادرسش کمترین مقدار را دارد
انتخاب Root Port برای هر سوئیچ
در مرحله ی بعدی، پس از انتخاب سوئیچ root، پروتکل STP برای سوئیچ های nonroot (همه ی سوئیچ ها به جز سوئیچ root) یک root port )RP) انتخاب می کند. RP هر سوئیچ، پورتی است که کمترین هزینه را برای رسیدن به سوئیچ root دارد.
احتمالا عبارت هزینه برای همه ی ما در انتخاب مسیر بهتر، روشن و مشخص باشد. اگر به دیاگرام شبکه ای که در آن سوئیچ root و هزینه ارسال اطلاعات روی هر پورت مشخص باشد توجه کنید، می توانید هزینه برقراری ارتباط با سوئیچ root را برای هر پورت به دست آورید. توجه کنید که سوئیچ ها برای به دست آوردن هزینه برقراری ارتباط با سوئیچ root، از دیاگرام شبکه استفاده نمی کنند، صرفا استفاده از آن برای درک این موضوع به ما کمک می کند.
تصویر 5-2 همان سوئیچ های مثال پیشین که در آن سوئیچ root و هزینه ی رسیدن به سوئیچ root را برای پورت های سوئیچ SW3 نشان می دهد.
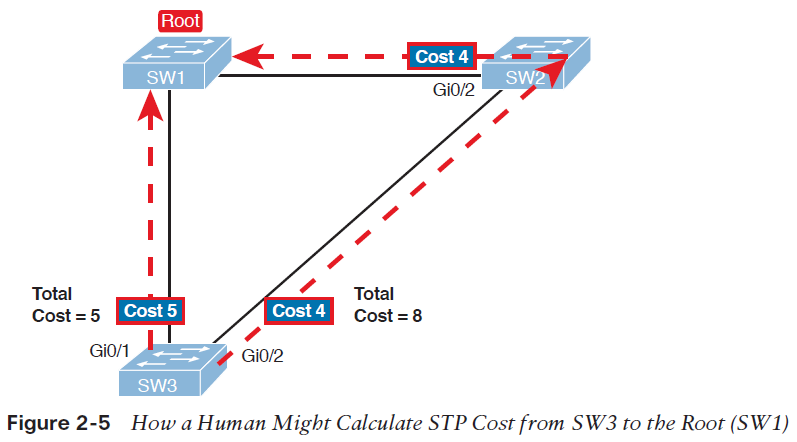
سوئیچ SW3 برای ارسال frameها به سوئیچ root، می تواند از دو مسیر استفاده کند: مسیر مستقیم که از پورت G0/1 خارج می شود و به سوئیچ root می رسد، و مسیر غیر مستقیمی که از پورت G0/2 خارج می شود و از طریق SW2 به سوئیچ root می رسد. برای هر یک از پورت ها، هزینه ی رسیدن به سوئیچ root برابر است با مجموع هزینه ی خروج از پورت هایی که frame ارسالی، برای رسیدن به سوئیچ root از آن ها عبور می کند (در این محاسبه، هزینه ورود آن frame به پورت ها حساب نمی شود). همانطور که مشاهده می کنید، مجموع هزینه ی مسیر مستقیم که از پورت G0/1 سوئیچ SW3 خارج می شود برابر 5 است، و مسیر دیگر دارای مجموع هزینه ی 8 می باشد. از آنجایی که پورت G0/1، بخشی از مسیری است که هزینه ی کمتری برای رسیدن به سوئیچ root دارد، سوئیچ SW3 این پورت را به عنوان root port انتخاب می کند.
سوئیچ ها با سپری کردن فرایندی متفاوت به همین نتیجه می رسند. آنها هزینه خروج از پورت خود را به root cost موجود در Hello BPDU ورودی از همان پورت اضافه می کنند و هزینه رسیدن به سوئیچ root از طریق آن پورت را به دست می آورند. هزینه خروج از هر پورت در پروتکل STP یک عدد صحیح (integer) می باشد که به هر پورت در هر VLAN اختصاص می یابد، تا پروتکل STP با استفاده از این مقیاس اندازه گیری بتواند تصمیم بگیرد که کدام پورت را به توپولوژی خود اضافه کند. در این فرایند سوئیچ ها، root cost سوئیچ های مجاور را که از طریق Hello BPDUهای دریافتی به دست می آورند، بررسی می کنند.

تصویر 6-2 یک مثالی از چگونگی محاسبه بهترین root cost و سپس انتخاب آن به عنوان root port را نشان می دهد. اگر به تصویر توجه کنید، خواهید دید که سوئیچ root پیام هایی(Hello) که root cost آن ها برابر صفر می باشد را ارسال می کند. هزینه رسیدن به سوئیچ root از طریق پورت های سوئیچ root برابر با صفر است.
در ادامه به سمت چپ تصویر توجه کنید که سوئیچ SW3، root cost دریافتی از طریق SW1 را (که برابر صفر است) با هزینه ی خروج از پورت G0/1 که آن Hello را دریافت کرده (5) جمع می کند و هزینه ارسال اطلاعات از طریق این پورت را به دست می آورد.
در سمت راست تصویر، سوئیچ SW2 متوجه شده که root cost آن برابر با 4 است. پس زمانی که SW2 یک Hello برای SW3 ارسال می کند، مقدار root cost آن را 4 قرار می دهد. در سمت دیگرهزینه ارسال اطلاعات از طریق پورت G0/2 در سوئیچ SW3 برابر 4 است، از اینرو سوئیچ SW3 این دو مقدار را با هم جمع می کند و به این نتیجه می رسد که هزینه ی رسیدن به سوئیچ root از طریق پورت G0/2 برابر 8 است.
با توجه به نتایج به دست آمده از آنجایی که پورت G0/1 نسبت به پورت G0/2 هزینه ی کمتری برای رسیدن به سوئیچ root دارد، پس سوئیچ SW3 پورت G0/1 را به عنوان RP انتخاب می کند. سوئیچ SW2 نیزبا گذراندن همین فرایند پورت G0/2 را به عنوان RP انتخاب می کند. سپس تمام سوئیچ ها، root port های خود را در وضعیت forwarding قرار می دهند.
انتخاب Designated Port در هر LAN segment (پورت کاندید)
پس از انتخاب سوئیچ root، در سوئیچ های nonroot، تمام root portها را مشخص کردیم و آنها را در وضعیت forwarding قرار دادیم. مرحله نهایی پروتکل STP برای تکمیل توپولوژی STP، انتخاب designated port در هر LAN segment است. در هر بخش(segment) از LAN، پورت سوئیچی که کمترین root cost را دارد و به آن بخش از LAN متصل است Designated port )DP) نامیده می شود. زمانی که یک سوئیچ nonroot می خواهد که یک Hello را ارسال کند، هزینه رسیدن به سوئیچ root را در root cost آن پیام قرار می دهد و ارسال می کند. دراینصورت پورت سوئیچی که کمترین هزینه را برای رسیدن به root دارد، در میان تمام سوئیچ هایی که به آن بخش متصل هستند، به عنوان DP در آن بخش شناخته می شود. در این مرحله اگر هزینه سوئیچ ها برای رسیدن به سوئیچ root برابر بود، پورت سوئیچی که BID کمتری دارد را به عنوان DP انتخاب می کنیم.
در تصویر 4-2 پورت G0/1 در سوئیچ SW2 که به سوئیچ SW3 متصل است، به عنوان DP انتخاب می شود.
پس از انتخاب DPها، تمام آن ها را در وضعیت forwarding قرار می دهیم.
مثالی که در تصاویر 3-2 تا 6-2 به نمایش گذاشته شد، تنها پورتی که نیازی ندارد تا در وضعیت forwarding قرار بگیرد، پورت G0/2 در سوئیچ SW3 است. درنهایت فرایند پروتکل STP کامل شد و جدول زیر وضعیت نهایی هر پورت و علت قرار گرفتن در آن وضعیت را نشان می دهد:
به صورت خلاصه اگر بخواهیم توضیح دهیم، در فرایند اجرای پروتکل STP:
• در قدم اول سوئیچ root انتخاب می شود که ابتدا تمام سوئیچ ها سعی می کنند خود را به عنوان root معرفی کنند، سپس سوئیچی که رقم BID آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب خواهد شد.
• در قدم دوم برای هر سوئیچ، پورتی که کمترین هزینه برای رسیدن به سوئیچ root دارد را به عنوان root port انتخاب می شود. سپس همه ی root portها را در وضعیت forwarding قرار می گیرند.
• در قدم سوم پورت های کاندید انتخاب می شوند و در وضعیت forwarding قرار می گیرند. در نهایت پورت هایی که وضعیتشان مشخص نشده در وضعیت blocking قرار می گیرند.
برچسب : root bridge چیست,نحوه کار پروتکل stp,اشنایی با پروتکل stp, نویسنده : شاهرخ urnetwork بازدید : 112
با منتشر شدن vSphere 6.7 به عموم مردم، طبیعی است که بحث های زیادی در اطراف ارتقا به آن وجود دارد. چگونه می توانیم ارتقا دهیم یا حتی چرا باید ارتقاء دهیم از سوالات پرطرفدار اخیرا بوده است. در این پست من این سؤالات و همچنین ملاحظاتی را که باید قبل از ارتقاء vSphere بررسی شود را پوشش خواهم داد. این ارتقاء دادن یک کار ترسناک یا غم انگیز نیست .

چرا ؟
خب بیاید با چرا شروع کنیم . چرا باید به vSphere 6.7 ارتقاء دهیم ؟ با VMware vSphere 6.7 سرمایه گذاری خود را در VMware تقویت می کنید. از آنجا که vSphere در قلب SDDC VMware قرار دارد ، ارائه و بنیاد ساختار اساسی برای استراتژی cloud شما ارائه میکند ، ارتقاء دادن باید اولویت اصلی ذهن شما باشد اما تنها پس از دقت و توجه به ویژگی ها و مزایا و اینکه چگونه آنها را به نیازهای کسب و کار بر گردانید. شاید تیم های امنیتی برای یکپارچگی دقیق تر برای هر دو سیستم Hypervisor و سیستم عامل مهمان درخواست کرده باشد بنابراین استفاده از vSphere 6.7 و پشتیبانی از Trusted Platform Module (TPM) 2.0 یا Virtual TPM 2.0 اکنون مورد نیاز است. اگر امنیت نباشد ، شاید انعطاف پذیری برنامه ای در vSphere 6.7 که آن پیشرفت های تکنولوژی NVIDIA GRID ™ vGPU ، اجازه می دهد تا مشتریان قبل از vMotion آنرا را متوقف کند و از VM های فعال شده با vGPU خلاص شوند. صرف نظر از خود ویژگی ها، مهم این است که اطمینان حاصل شود ویژگی های مورد نیاز به طور مناسب به شرایط کسب و کار برمی گردند.
چرا
یکی دیگر از دلایل اینکه چرا باید ارتقاء پیدا کنیم به علت پایان پشتیبانی محصول یا کار آن است. اگر قبلا شنیده باشید، VMware vSphere 5.5 به سرعت به پایان عمر خود نزدیک می شود. تاریخ دقیق پایان کلی پشتیبانی برای vSphere 5.5 در روز 19 سپتامبر 2018 است. با در نظر داشتن این موضوع، ارتقاء باید در خط مقدم طرح های شما باشد. اما خبر خوب در مورد پایان سافتن vSphere 5.5 ، این است که VMware پشتیبانی عمومی از vSphere 6.5 را تا پنج سال کامل از تاریخ انتشار آن تا تاریخ 15 نوامبر 2021 گسترش داده است. اگر شما از من بپرسید این نکته بسیار شگفت انگیزی است. نقطه عطف بعدی درک چگونگی به ارتقاء به vSphere 6.5 /6.7 است که مشتریان را قادر می سازد تا مزایای یک راه حل نرم افزاری SDDC که کارآمد و امن است را داشته باشند .
چگونه
خب اجازه دهید در مورد چگونگی صحبت کنیم. چگونه ارتقا دهیم؟ برای شروع ، VMware انواع بسیاری از مستندات را برای کمک به نصب یا ارتقاء VMware vSphere با استفاده از VMware Docs فراهم می کند. سایت VMware Docs به رابط بسیار ساده تر که شامل قابلیت جستجو بهتر در نسخه ها و همچنین یک گزینه برای ذخیره اسناد در MyLibrary برای دسترسی سریع برای بعد به روز شده است . vSphere Central یک مخزن غظیم از منابع vSphere است از جمله وبلاگ ها، KB ها، فیلم ها، و walkthroughs ها که برای کمک به مشتریان است تا به سرعت اطلاعات مورد نیاز خود را پیدا کنند. بعدا، هر گونه راه حل VMware که با محیط شما مرتبط باشد را بررسی کنید ، مانند مدیریت بازیابی سایت SRM)، Horizon View Composer) ، یا VMware NSX . قبل از شروع ، همچنین تعیین کنید که آیا تنظیم فعلی شما از معماری جاسازی شده یا خارجی برای SSO / PSC استفاده می کند، به این دلیل که ممکن است مسیر ارتقا شما را تحت تاثیر قرار دهد.

یک عامل کلیدی در کمک به اینکه چگونه به ارتقاء محیط vSphere بپردازد، بررسی در محدوده سازگاری های نسخه میباشد . همه نسخه های vSphere قادر به ارتقا به vSphere 6.7 نیستند. به عنوان مثال، vSphere 5.5 یک مسیر ارتقاء مستقیم را به vSphere 6.7 ندارد. اگر شما در حال حاضر vSphere 5.5 را اجرا می کنید، قبل از ارتقا به vSphere 6.7 ابتدا باید به vSphere 6.0 یا vSphere 6.5 ارتقا دهید. بنابراین قبل از اینکه شما به نصب جدیدترین نسخه vSphere 6.7 ISO خود بپردازید ، یکبار مسیر خود را اینجا انجام دهید و هر محیطی را که ممکن است در نسخه پایین تر از vSphere 6.0 اجرا کنید در نظر داشته باشید. قبل از شروع ارتقاء vSphere 6.7 ، این محیط قدیمی را به یک نسخه سازگار vSphere ارتقا دهید. پس از بحث درباره چگونگی ارتقاء، ما باید به طور طبیعی در مورد برنامه ریزی ارتقاء صحبت کنیم.
یادآوری:روش های پشتیبانی شده برای ارتقاء میزبان های vSphere شما عبارتند از: با استفاده از ESXi Installer، دستور ESXCLI از داخل (ESXi Shell، vSphere Update Manager (VUM و Auto Deploy.
برنامه ریزی
راز ارتقاء موفق با شروع برنامه ریزی شده است. ما درباره نحوه شروع آماده سازی برای ارتقاء vSphere با درک چگونگی و چرایی آن بحث کرده ایم. گام های منطقی بعدی شروع برنامه ریزی است. این جایی است که شما خود را در حال بررسی یافته ها در محیط خود و همچنین جمع آوری فایل های نصب و راه اندازی آنها برای ارتقاء. آماده میکنید . بسیار مهم است که ترتیب و مراحل سایر محصولات VMware را مشخص کنید بنابراین شما کاملا درک می کنید که باید قبل یا بعد از vCenter Server و ESXi باید چه کنید. ارتقاء برخی محصولات غیرمجاز ممکن است نتایج بدی داشته باشد که می تواند یک مشکل را در برنامه ارتقاء شما قرار دهد. برای مشاهده جزئیات بیشتر با بررسی vSphere 6.7 Update Sequence KB Article شروع کنید. در طول برنامه ریزی مشتریان باید تمام محصولات ، نسخه ها و واحدهای تجاری را در نظر بگیرند که ممکن است در طول و یا بعد از ارتقاء تحت تاثیر قرارگیرند. برنامه ریزی باید شامل تست آزمایشگاهی ارتقا باشد تا اطمینان حاصل شود که روند و نتایج را درک کنید. انجام یک بررسی سلامتی vSphere ممکن است بهترین پیشنهادی باشد که میتوانم بدهم . ارزیابی vSphere می تواند به کشف منابع هدر رفته، مشکلات محیطی و حتی مواردی ساده مانند تنظیم نادرست NTP یا DNS کمک کند. در نهایت تمام اطلاعات محاسباتی ، ذخیره سازی ، شبکه ایی و بک آپ های vendors را برای سازگاری با vSphere 6.7 جمع آوری کنید. هیچ چیز بدتر از آن نیست که بعد از ارتقاء محیط خود متوجه شوید که یک rd party vendor3 نسخه سازگار با vSphere را ارائه نکرده باشد.
ملاحظات ارتقاء
برای کمک بیشتر به مشتریان در ارتقاء vSphere ، من مجموعه کاملی از ملاحظات ارتقا را برای کمک به شما در شروع برنامه ارتقاء به vSphere 6.7. جمع آوری کرده ام.
ملاحظات vSphere
از آنجا که vSphere پایه ای برای SDDC است، بسیار مهم است که قابلیت همکاری آن را با نسخه های فعلی نصب شده در پایگاه داده های شما بررسی شود .
- An Upgrade from vSphere 5.5 to vSphere 6.7 GA directly is currently not supported
- vSphere 6.0 will be the minimum version that can be upgraded to vSphere 6.7
- vSphere 6.7 is the final release that requires customers to specify SSO sites.
- In vSphere 6.7, only TLS 1.2 is enabled by default. TLS 1.0 and TLS 1.1 are disabled by default.
- Due to the changes done in VMFS6 metadata structures to make it 4K aligned, you cannot upgrade a VMFS5 datastore inline or offline to VMFS6, this stands true for vSphere 6.5 & vSphere 6.7. (See KB2147824)
ملاحظات سرور vCenter
(vCenter Server Appliance (VCSA در حال حاضر به طور پیش فرض برای سرور vCenter استفاده می شود. vCenter Servers topology deployment باید در مرکز برنامه ریزی ارتقاء vSphere شما باشد. چه از یک (exteal Platform Services Controller (PSC یا embedded استفاده کنید ، به یاد داشته باشید که توپولوژی را نمی توان در vSphere 6.0 یا 6.5 تغییر داد. اگر از vSphere 5.5 ارتقا می دهید ، تغییرات توپولوژی و ادغام SSO Domain Consolidation پشتیبانی می شود ، اما قبل از ارتقا به vSphere 6.x باید انجام شود.
- The vSphere 6.7 release is the final release of vCenter Server for Windows. After this release, vCenter Server for Windows will not be available
- vCenter Server 6.7 does not support host profiles with version less than 6.0 (See KB52932)
- vCenter Server 6.7 supports Enhanced Linked Mode with an Embedded PSC (Greenfield deployments only)
- If vCenter High Availability (VCHA) is in use within your vSphere 6.5 deployment, you must remove the VCHA configuration before attempting an upgrade.
معیارهای سازگاری محصولات VMware
گاهی اوقات با انتشار نرم افزارهای جدید، دیگر محصولاتی که بر پایه اجزای ارتقا یافته قرار دارند، ممکن است در روز از اول محصولات GA کاملا پشتیبانی نشوند یا سازگار نباشند. راهنمای سازگاری VMware باید یکی از اولین توقف های شما در طول مسیر ارتقاء vSphere باشد. با استفاده از این راهنما ها مطمئن میشوید که اجزای شما و همچنین مسیر ارتقاء مورد نظر شما ، پشتیبانی می شود.
با این محصولات زیر در حال حاضر سازگار با vSphere 6.7 GA نیستند.
- VMware Horizon
- VMware NSX
- VMware Integrated OpenStack (VIO)
- VMware vSphere Integrated Containers (VIC)
ملاحظات سخت افزاری
ارتقاء vSphere نیز می تواند توسط سخت افزار ناسازگار متوقف شود . با توجه به این موضوع، قبل از ارتقاء ، بایستی BIOS سخت افزار و سازگاری پردازنده را بررسی و مشاهده کنید. برای مشاهده لیست کامل CPU های پشتیبانی نشده، مقالهvSphere 6.7 GA Release Notes منتشر شده در بخشی تحت عنوان “Upgrades and Installations Disallowed for Unsupported CPUs“ را مرور کنید.
- vSphere 6.7 no longer supports certain CPUs from AMD & Intel
- These CPUs are currently supported in the vSphere 6.7 release, but they may not be supported in future vSphere releases;
- Intel Xeon E3-1200 (SNB-DT)
- Intel Xeon E7-2800/4800/8800 (WSM-EX)
- Virtual machines that are compatible with ESX 3.x and later (hardware version 4) are supported with ESXi 6.7
- Virtual machines that are compatible with ESX 2.x and later (hardware version 3) are not supported
سازگاری سخت افزار و نسخه hypervisor و سطح ماشین مجازی باید به عنوان بخشی از برنامه ریزی شما نیز در نظر گرفته شود. به یاد داشته باشید نسخه سخت افزاری VM اکنون به عنوان سازگاری VM شناخته می شود. توجه: ممکن است لازم باشد سازگاری ماشین مجازی را قبل از استفاده از آن در vSphere 6.7 ارتقا دهید.
جمع بندی
جهت یاد آوری باید خاطر نشان کنیم که بخش چرا و چگونه را با تمرکز و دقت بالا مطالعه کنید. بدون داشتن تمرکز بر اینکه چه چیزی ارتقاء را در شرایط رضایت بخش به ارمغان می آورد یا درک تمام مزایای یکپارچه، در حقیقت آنها به راحتی می توانند از بین بروند. برنامه ریزی بخش بسیار مهم در مسیر ارتقاء است و بدون برنامه ریزی ممگن است در سازگاری ورژن ها به مشکل بر بخورید. اجرا ؛ بدون داشتن تمرکز و درک ویژگی ها یا روش ها و همچنین برنامه ریزی پیاده سازی ارتقاء vSphere ، شما قادر نخواهید بود که با موفقیت این کار را انجام دهید.
پس به یاد داشته باشید : تمرکز، برنامه ریزی، اجرا !
شبکه و تجهیزات شبکه...برچسب : مجازی سازی,vmware چیست,اشنایی باvsphere, نویسنده : شاهرخ urnetwork بازدید : 148
FT یا Fault Tolerance قابلیتی است که به شما ویژگی های دسترس پذیری بالاتر و محافظت بیشتری از ماشین ها ، در مقایسه با زمانی که از قابلیت HA استفاده میکنید ، ارائه میکند. از نکات منفی قابلیت HA زمان بر بودن بازگشت از Failover و داشتن Down Time است. FT از ورژن 4 معرفی شد اما تا ورژن 6 استفاده نمیشد.
نحوه کار FT
FT فقط برای ماشین هایی با درجه اهمیت بسیار بالا ، با ساختن یک ماشین یکسان دیگر از آن و دردسترس قرار دادن آن برای استفاده در زمان های Failover عمل میکند. به ماشینی که توسط این قابلیت محافظت میشود Primary و به ماشین دوم که یک Mirror از آن است Secondary میگویند. این دو ماشین به طور متناوب وضعیت یکدیگر را زیرنظر میگیند . در زمانی که هاست ماشین Primary از دسترس خارج شود ، ماشین Secondary به سرعت فعال و جایگزین آن میشود و یک ماشین Secondary دیگر ایجاد و وضعیت FT به حالت طبیعی باز میگردد ، و زمانی که هاست ماشین Secondary از دسترس خارج شود یک ماشین Secondary دیگر جایگزین آن میشود. در هر دو حالت کاربر هیچ وقفه ایی در کار ماشین احساس نمیکند و دیتایی از بین نمیرود.
به منظور اطمینان از در دسترس بودن حداقل یکی از ماشین ها ، ماشین Primary و Secondary نمیتوانند هم زمان در یک هاست حضورداشته باشند . همچنین FT از فعال بودن هر دو ماشین در زمان برگشت از وضعیت Failover به منظور جلوگیری از “split-brain” محافظت میکند.
موارد استفاده Fault Tolerance
زمانی که ماشین Secondary فعال شده و نقش ماشین Primary را اجرا میکند ، وضعیت ماشین به طور کامل بازیابی میشود ، یعنی محتویات رم ، برنامه های در حال اجرا و وضعیت پردازشی بدون هیچ تاخیر و نیاز به Load مجدد .به عنوان مثال از این قابلیت برای زمانی که سرویسی داریم که نیاز داریم تمام مدت ، بدون هیچ تاخیری در حال اجرا باشد ، استفاده میشود.
نیازمندی ها و محدودیت های Fault Tolerance
CPU هاست ها باید با V-motion و یا Enhanced V-motion سازگار باشد و از MMU پشتیبانی کند و حتما از شبکه 10G در بستر شبکه استفاده شود. در هر هاست حداکثر تا 4 ماشین را میتوان توسط FT محافظت کرد (هر دو Primary و Secondary شمارش میشوند) اما میتوان این محدودیت را از طریق Advanced Option افزایش داد.
تا آن زمان فقط ماشین هایی که یک هسته CPU داشتند را میتوانستید توسط FT محافظت کنید اما اکنون تا چهار هسته CPU را میتوان محافظت کرد .
در ورژن 6 به بعد ، دیسک ماشین Secondary میتواند روی LUN دیگری در Storage دیگر باشد زیرا دو ماشین در حال Sync شدن هستند . ماشین Secondary برای اپدیت شدن وضعیت اش باید محتویات Memory و CPU را سینک کند ، برای اینکار باید پورت Vm keel network ایی داشته باشیم . به همین دلیل VMware توصیه میکند برای پورت فیزیکی از کارت 10G ستفاده شود.
قالبیت ها و Device هایی که با این ویژگی از دست خواهید داد:
- از ماشینی که FT enabled میشود نمیتوان Snapshot گرفته و Snapshot های قبلی را باید حذف کرد.
- ماشینی که FT enabled میشود نباید Linked clone باشد و نمیتوان از خود آن هم Linked clone گرفت.
- قابلیت VMCP را برای ماشین نمیتوان فعال کرد.
- IO filters
- Virtual Volume data store
- Storage-based policy management
- Physical Raw Disk mapping (RDM)
- CD-ROM or floppy virtual devices
- N Port ID Virtualization (NPIV)
- USB and sound devices
- NIC pass through
- Hot-plugging devices
- Serial or parallel ports
- Video devices that have 3D enabled
- Virtual EFI firmware
- Virtual Machine Communication Interface (VMCI)
- 2TB+ VMDK
نکته : به منظور افزایش Availability میتوانید از FT در کنار قابلیت DRS ، فقط زمانی که ویژگی EVC فعال شده باشد استفاده کنید.
قبل از فعال کردن FT مطمئن شوید که :
- ماشین و هاست های شما شرایط لازم برای فعال کردن FT را دارند
- وضعیت شبکه هر هاست را بررسی کنید
- کارت شبکه V-motion بررسی شود
- کلاستر HA ایجاد و فعال شود
- CPU شما پشتیبانی شود
- HV در تنظیمات BIOS هاست فعال باشد
- فایل های ماشین ها در فضای Shared storage باشد
- حداقل 3 هاست داشته باشید
- حداکثر تا 4 هسته را میتوان FT کرد
- ماشین هایی که FT enabled میشود Snapshot نداشته باشد
- VMware tools نصب باشد
- EVC در صورت نیاز فعال باشد
- هیچ گونه Removable Media نداشته باشد
- FT دوبرابر شرایط معمول منابع مصرف میکند
- توصیه میشود کارت شبکه 10G dedicated استفاده شود
- CPU و Memory قابلیت Hot plug نداشته باشد
- هر هاست نهایتا تا 8 هسته FT شده میتواند داشته باشد
برای مثال : با 3 هاست ، 3 ماشین 4 کور میتوانیم داشته باشیم (ماشین Secondary هم حساب میشود)
فعال کردن قالبیت FT :
ابتدا یک کارت شبکه اختصاصی میسازیم ، برای اینکار به تب VM keel adapter رفته و کارت شبکه اضافه میکنیم ، سپس برروی ماشینی که میخواهیم محافظت شود راست کلیلک کرده و Fault tolerance را فعال میکنیم ، پس از آن پنجره ای باز میشود که از ما محل ماشین دوم ، محل دیسک و بعد هاست را انتخاب مکنید و در نهایت Finish را انتخاب میکنیم.
پس از فعال کردن FT رنگ آیکون ماشین به آبی تغیر رنگ میدهد. برای تست FT و اطمینان از عملکرد صحیح آن میتوانید از گزینه Test Failover استفاده کنید.
شبکه و تجهیزات شبکه...برچسب : Fault Tolerance چیست,مجازی سازی,تحمل خطلا در مجازی سازی,Fault Tolerance در مجازی سازی, نویسنده : شاهرخ urnetwork بازدید : 126
Vapp یک Object است که اسمش ما را به یاد Application Vitrtualization می اندازد اما در اصل ارتباطی با آن ندارد . Vapp در واقع یک Resource Pool است که feature های اضافه ایی را به ما میدهد . از مهم ترین این ویژگی ها میتوان به Start up و Shut down order اشاره کرد .
نکته : برای بهره مندی از این امکان ، باید در سطح کلاستر قابلیت DRS فعال شده باشد.
علت نام گذاری این ویژگی آن است که ، زمانی که ما چند ماشین مجازی داریم که آنها با ارتباط و همکاری یکدیگر سرویسی را ارائه میکنند که به عنوان یک اپلیکشن ارائه میشود ، به عنوان مثال چند ماشین داریم که سرویس اتوماسیون را ارائه میکنند . در نتیجه تنظیمات Resource آنها با یکدیگر مربوط و دستورات روشن یا خاموش شدن این ماشین ها در ارتباط با هم است. به این دلیل یک Vapp میسازیم و این ماشین ها را داخل آن قرار میدهیم . (برای ساخت Vapp میتوان از یک Vapp موجود هم Clone گرفت)
Vapp ها حالت Container دارند ، یعنی ماشین داخل آن اضافه میشوند .
همچنین میتوان یک Vapp را مانند یک ماشین معمولی روشن ، خاموش و یا ری استارت کرد.
تنظیماتی که میتوان با کمک Vapp اعمال کرد شامل : کنترل ترتیب روشن یا خاموش شدن ماشین ها و تنظیمات Resource Pool و قابلیت IP Allocation میباشد.
Vapp ها در سطح Host and Clusters view و Template view نمایش داده میشوند.
نکته : اولویت خاموش شدن ماشین ها ، برعکس اولویت روشن شدنی است که تنظیم کرده اید !
نکته : در صورت حذف کردن Vapp ، اگر داخل آن ماشینی وجود داشته باشد ، آن ماشین ها نیز حذف خواهند شد . (Delete From Disk)
همانطور که بیان شد Vapp در سناریوهای بازگشت از حادثه (disaster recovery scenarios) ، زمانی که میخواهید به صورت خودکار و سریع تعداد زیادی ماشین وابسته به یکدیگر را با یک کلیک یا دستور روشن کنید ، کارآمد هستند.
شبکه و تجهیزات شبکه...برچسب : مجازی سازی,vmware vapp چیست؟,vapp چیست؟, نویسنده : شاهرخ urnetwork بازدید : 153
Distributed Resource Scheduler یا به اختصار DRS ابزاری است که وضعیت هاست های فیزیکی ما را از نظر میزان منابع زیر نظر میگیرد و براساس آن ماشین های مجازی را به نحوی در بین هاست ها جابجا میکند تا منابع تمام هاست به طور بهینه و یکسان مورد استفاده قرار گیرد و چنانچه ماشین های مجازی یک هاست با کمبود منابع مواجه شوند با انتخاب بهترین هاست از نظر منابع کافی ، ماشین را به آن هاست منتقل میکند.
همانطور که قبلا اشاره شد ، اینFeather یکی از ویژگی های Cluster است و برای فعال کردن آن باید Cluster داشته باشیم.
ویژگی های کلاستر :
DRS:
این ویژگی هاست های ما را از نظر میزان مصرف RAM و CPU ، و در ورژن 6.5 از نظر Network ، Load balance میکند . معمولا این Feather را در کنار گزینه های دیگر مانند HA و یا FT ، به منظور بهره وری هرچه بیشتر از قابلیت های vSphere فعال میکنند.
این ویژگی از طریق V-motion عمل مکیند و در دو زمان بخصوص اعمال میشود:
- زمانی که یک ماشین درحال روشن شدن است ، بهترین هاست برای روشن شدن ماشین در آن را انتخاب میکند
- زمانی که Load هاست های ما به هم میریزد
با انتخاب گزینه Manual ، چه در زمان روشن شدن ماشین و چه در زمان بهم ریخت Load هاست ها ، به ما فقط Recommends میدهد و خود ما باید دستور جابجایی ماشین ها را صادر کنیم.
با انتخاب گزینه Fully automated در هر دو حالت به صورت خودکار جابجایی اعمل میشود .
و با انتخاب گزینه Partially automated ، در زمان روشن شدن ماشین جابجایی به صورت خودکار انجام میشود ، اما زمانی که Load هاست ها بهم میریزد ، به ما Recommend میدهد و خود ما باید دستور جابجایی ماشین ها را صادر کنیم.
شما میتوانید Role هایی تنظیم کنید تا به عنوان مثال دو ماشین (DC) که سرویس های Parallel ارائه میکنند هم زمان در یک هاست نباشند و یا نرم افزاری که Database ایی دارد که باید درکنار ماشین خودش باشد ، در یک هاست قرار بگیرد و یا ماشینی که دانگل دارد و باید در یک هاست بخصوصی باشد .
در این Role ها 4 حالت به تفکیک ذیل داریم :
- Must
- Must not
- Should
- Should not
نکته : گزینهShould به عنوان توصیه و گزینه Must حالت اجبار دارد.
Predictive DRS:
اگر شما نرم افزار vRealize را داشته باشید ، این نرم افزار طبق گزارشات خود اطلاع دارد که به عنوان مثال شنبه 8 صبح Domain Controller ، Load زیادی دارد پس وضعیت آنرا Normal در نظر میگیرد. Predictive DRS از اطلاعات Historical این نرم افزار استفاده میکند و زمان هایی که میداند الگوی Load هاست به زودی تغییر می کند ، قبل از رسیدن به آن زمان مشخص ، در صورت نیاز ماشین را جابجا میکند تا دچار Bottleneck نشود.
EVC:
قابلیت Enhanced vMotion Compatibility یا EVC ، پردازشگر های هم برند اما غیر هم خانواده را با هم Compatible میکند تا بتوانیم V-motion و FT را فعال کنیم. این گزینه یک لایه نرم افزاری یا Mask را بین VCPU و PCPU اعمال میکند. (در سری سرورهای G8 و G9 نیازی به فعال کردن این گزینه ندارید)
نکته: زمان روشن بودن ماشین ها نمیتوانید این گزینه را فعال کنید . بهتر است هنگام راه اندازی بستر این گزینه فعال شود.
شبکه و تجهیزات شبکه...برچسب : vapp,vmware vapp, نویسنده : شاهرخ urnetwork بازدید : 88
آرشیو مطالب
پيوندهای روزانه
لینک دوستان
- کرم سفید کننده وا
- دانلود آهنگ جدید
- خرید گوشی
- فرش کاشان
- بازار اجتماعی رایج
- خرید لایسنس نود 32
- هاست ایمیل
- دانلود آهنگ جدید
- خرید بانه
- اکانت اسپاتیفای
- ایران جابینو
- خرید بک لینک
- کلاه کاسکت
- موزیک باران
- نمایندگی شیائومی مشهد
- مشاوره حقوقی تلفنی با وکیل
- کرم سفید کننده واژن
- دانلود فیلم
- آرشیو مطالب
- فرش مسجد
- دعا
- رنگ مو
- شارژ
- سرور hp
- راه اندازی دیتا سنتر
- سوئیچ سیسکو
- لایسنس iLO
- روتر سیسکو
- HP c3000 Enclusure
- سرور HP نسل G10
- استوریج hp 3par 8200
- استاندارد سازی اتاق سرور